Second Brain kiểu Karpathy - áp dụng được hay chỉ đang FOMO?
Gist về LLM Wiki của Andrej Karpathy đang viral. Mình thử nhìn kỹ hơn: idea hay ở đâu, ai nên áp dụng, và làm sao để tránh FOMO.
May 12, 2026 · 27 min read
Mấy ngày gần đây mình thấy Twitter, Reddit, Hacker News, rồi cả mấy group dev ở Việt Nam đều nhắc tới một gist của Andrej Karpathy. Nội dung là cách ổng tự xây một kiểu wiki cá nhân dùng LLM để quản lý kiến thức. Nhiều người gọi nó là "Second Brain kiểu Karpathy".
Mình cũng tò mò nên vào đọc gist gốc. Đọc xong thì đọc thêm bài phân tích của Vĩ, Mod Nghiện AI, trên Facebook và bài của anh Goon Nguyễn trên Substack.
Mỗi bài cho mình thêm một góc nhìn. Vĩ nói rất hay về chuyện xem kiến thức như một codebase. Anh Goon Nguyễn thì đặt câu hỏi thẳng hơn về việc kiểm chứng, nhất là khi "bộ não thật" của mình chưa đủ vững.
Ý tưởng của Karpathy hay thật. Nhưng mình không muốn viết một bài kiểu fanboy "mọi người phải làm theo ngay".
Mình muốn hỏi thẳng hơn:
Mọi người đang thật sự hiểu và áp dụng nó, hay chỉ đang FOMO vì Karpathy nói?
Trong gist, Karpathy không gọi hệ thống này là "Second Brain". Ổng gọi nó là LLM-maintained wiki hoặc bộ não ngoài (exocortex). "Second Brain" là khái niệm do Tiago Forte phổ biến từ trước. Hai thứ có điểm giao nhau, nhưng không giống nhau hoàn toàn. Mình dùng "Second Brain" trong bài vì đây là cách cộng đồng đang gọi khi nói về hệ thống của Karpathy.
Karpathy là ai mà lời ổng nói lại có trọng lượng như vậy
Với bạn nào chưa biết thì Karpathy là một trong những cái tên rất lớn trong giới AI. Ổng từng là Director of AI ở Tesla, co-founder của OpenAI, và từng dạy CS231n ở Stanford - một trong những khóa deep learning nổi tiếng nhất.
Gần đây ổng còn làm nhiều video giáo dục rất chỉn chu về LLM, tokenizer, backpropagation, neural network. Kiểu video mà dân kỹ thuật xem xong thấy đã, vì mọi thứ được giải thích rõ ràng chứ không màu mè.
Nói ngắn gọn: Karpathy đăng gì thì cộng đồng lắng nghe.
Không chỉ vì ổng giỏi. Mà vì ổng hiếm khi nói kiểu marketing. Ổng thường nhìn mọi thứ như một hệ thống: đầu vào, đầu ra, trạng thái, vòng lặp, điểm lỗi, công cụ hỗ trợ.
Nên khi ổng nói về cách học, cách ghi chú, cách dùng AI, mọi người không xem đó là một mẹo năng suất cho vui. Nó giống một quy trình mà một người rất giỏi đã dùng thật.
Đó là lý do một gist khá ngắn cũng tạo được sóng. Không phải vì ý tưởng này hoàn toàn mới. Obsidian, Zettelkasten, PARA, RAG, personal wiki đều có từ lâu rồi.
Nhưng khi Karpathy gom chúng lại thành một hệ thống đang chạy được, cộng đồng nhìn thấy một phiên bản đáng tin hơn.

LLM Wiki của Karpathy - tóm tắt ngắn
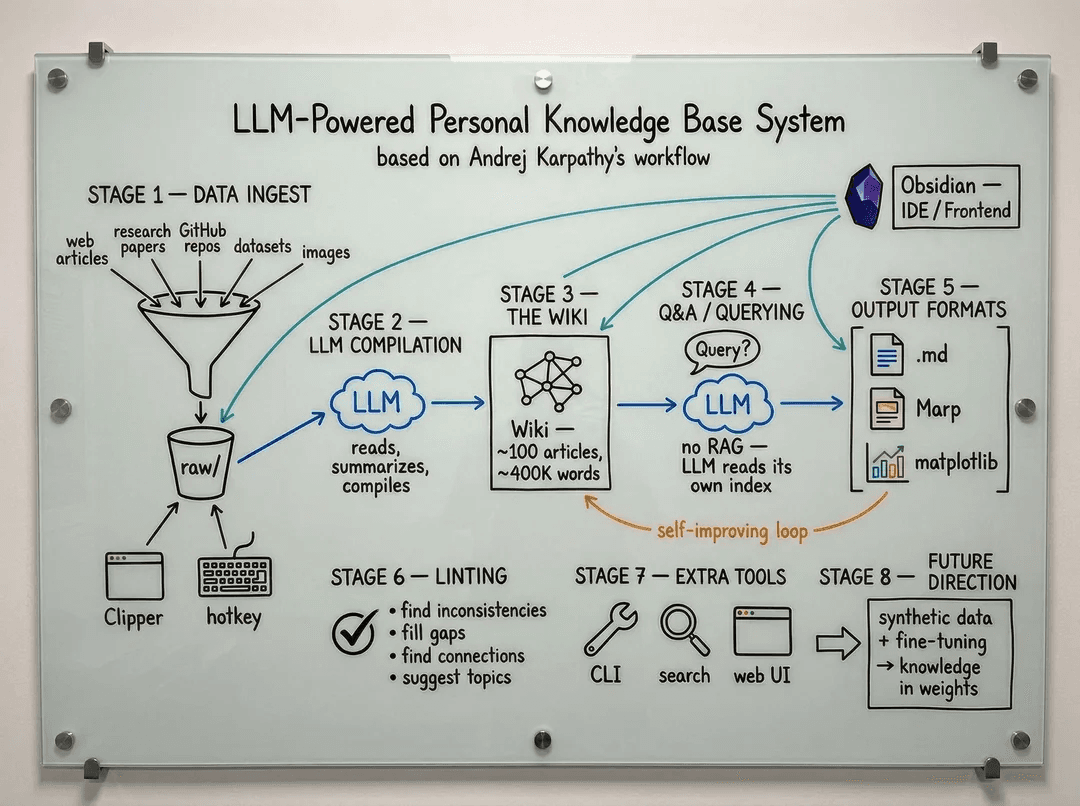
Đọc kỹ gist thì cách làm của Karpathy khá rõ. Không màu mè. Không cần app mới. Không cần database phức tạp.
Nền chính chỉ là một folder trên máy, Markdown, GitHub và LLM.
Ổng không muốn dùng RAG theo kiểu truyền thống: mỗi lần hỏi thì truy vấn tài liệu thô, nhồi ngữ cảnh vào prompt, rồi để model tổng hợp lại từ đầu. Cách đó có ích, nhưng nó không tạo ra nhiều kiến thức tích lũy. Mỗi lần hỏi gần như là một lần làm lại.
Karpathy muốn xây một wiki có tính tích lũy. Nghĩa là LLM không chỉ trả lời câu hỏi. Nó còn duy trì một lớp kiến thức đã được xử lý, đã liên kết lại, đã cập nhật.
Lần sau hỏi thì hỏi trên lớp wiki đó. Không phải lúc nào cũng quay lại đống tài liệu thô.
Cấu trúc gồm 3 lớp:
- Tài liệu gốc: tài liệu ban đầu, paper, bài viết, code, transcript, ảnh, ghi chú thô. Đây là nguyên liệu. Giữ nguyên, không sửa.
- Wiki: các file Markdown đã xử lý. Có tóm tắt, trang khái niệm, trang nhân vật/tổ chức, liên kết chéo, nhận định, mâu thuẫn, câu hỏi mở.
- Bộ quy tắc: file như
CLAUDE.mdhoặcAGENTS.md, định nghĩa quy ước, cách vận hành, cách đặt tên, cách cập nhật, cách LLM phải hành xử.
Quy trình xoay quanh 3 thao tác chính.
Nạp nguồn là đưa tài liệu mới vào. LLM đọc, tóm tắt, cập nhật trang liên quan, thêm liên kết, ghi lại thay đổi.
Hỏi wiki là đặt câu hỏi trên lớp kiến thức đã xử lý. Không chỉ hỏi "tóm tắt bài này", mà hỏi những câu cần tổng hợp nhiều nguồn.
Rà soát wiki là kiểm tra định kỳ. Tìm mâu thuẫn, nhận định đã cũ, trang mồ côi, khoảng trống kiến thức, liên kết hỏng.
Công cụ thì rất đời thường: Obsidian làm nơi đọc và chỉnh wiki, Obsidian Web Clipper để lưu bài viết, qmd cho tìm kiếm local, Dataview để truy vấn metadata, Marp để tạo slide.
Nhưng điểm quan trọng không nằm ở tên công cụ. Điểm quan trọng là cấu trúc: tài liệu gốc ở một nơi, kiến thức đã xử lý ở một nơi, quy tắc vận hành ở một nơi.
Kiến thức như một codebase
Đây là insight mình thích nhất từ bài phân tích của Vĩ.
Karpathy là kỹ sư, nên ổng nhìn kiến thức giống cách kỹ sư nhìn codebase. Một codebase không được bảo trì thì sẽ mục dần. Phụ thuộc cũ. Cách đặt tên lệch nhau. Logic trùng lặp. Comment sai. Module không ai dám đụng.
Bug không hiện ra ngay. Nhưng chất lượng giảm từng chút một.
Kiến thức cá nhân cũng vậy.
Các bạn có thể đọc rất nhiều. Nhưng nếu mớ kiến thức đó không được nối lại, kiểm tra lại, cập nhật lại, nó sẽ thành một đống file rời.
Có thứ đúng ở thời điểm mình đọc, nhưng sai ở hiện tại. Có thứ mâu thuẫn nhau mà mình không biết. Có thứ quan trọng nhưng bị chôn trong bookmark, PDF, screenshot, chat history.
Có thấy quen không? Mình thì có.
Bộ não bạn hôm nay nếu không được nuôi dưỡng đúng cách có thể kém hơn bộ não bạn 6 tháng trước.
Câu này nghe hơi đau, nhưng mình thấy đúng. Không phải vì mình quên sạch. Mà vì môi trường thay đổi nhanh hơn tốc độ tự cập nhật của mình.
Trong AI, một paper cách đây 6 tháng có thể đã cũ. Một best practice năm ngoái có thể thành anti-pattern. Một quan điểm mình từng tin cũng có thể cần xem xét lại.
Nếu xem kiến thức như codebase, câu hỏi sẽ đổi khác.
Mình không chỉ hỏi "mình đã lưu cái này chưa?". Mình sẽ hỏi: phần nào trong kiến thức đang cũ? Có note nào mâu thuẫn nhau không? Có khái niệm nào mình dùng hoài mà chưa định nghĩa rõ? Có nguồn nào mình tin quá mức nhưng chưa đối chiếu? Có chỗ nào cần gom lại từ ghi chú rời thành một mô hình tư duy rõ ràng hơn không?
Đây là điểm làm LLM Wiki khác với ghi chú thông thường. Nó không chỉ lưu. Nó còn bảo trì.
AI để suy nghĩ khác AI để xây kiến thức
Chỗ này mình nghĩ ít người để ý, nhưng nó quan trọng.
Mình thấy hầu hết anh em đang dùng AI kiểu này: mở ChatGPT hay Claude lên, quăng câu hỏi, nhận trả lời, chỉnh vài lượt cho ưng, xong đóng tab. Mình cũng vậy.
Đó là dùng AI để suy nghĩ ngắn hạn.
Cách này rất hữu ích. Mình dùng hằng ngày. Nhưng nó giống RAM hơn là ổ cứng. Nó giúp mình trong một phiên làm việc.
Nếu không lưu lại, không cấu trúc lại, không đưa ngược vào hệ thống của mình, thì vài ngày sau gần như mất.
LLM Wiki của Karpathy đi theo hướng khác: dùng AI để tích lũy và hệ thống hóa kiến thức dài hạn.
Khác biệt nằm ở kết quả cuối cùng.
Chat thông thường tạo ra câu trả lời trong một phiên làm việc. Wiki thì tạo ra những file Markdown có thể sống lâu trong thư mục của mình.
Chat giúp mình xử lý câu hỏi hiện tại. Wiki giúp mình tích lũy ngữ cảnh cho những câu hỏi sau này.
Chat phụ thuộc vào nền tảng. Wiki nằm trên máy mình, trên GitHub của mình, và đọc được bằng bất kỳ editor nào.
Theo chia sẻ trong cộng đồng, sau một năm wiki của Karpathy có khoảng 100 bài và hàng trăm nghìn từ. Dù OpenAI, Anthropic, Notion hay app nào đó đổi chính sách, folder Markdown đó vẫn còn.
Đây là phần nhiều người bỏ qua khi FOMO. Họ tưởng điểm chính là "dùng AI để ghi chú nhanh hơn".
Nhưng điểm sâu hơn là: dùng AI để biến việc học thành một hệ thống có khả năng ghi nhớ và tích lũy.
Chat với AI là trí nhớ ngắn hạn. Wiki được AI duy trì là trí nhớ dài hạn. Hai thứ đều có ích, nhưng giải quyết hai bài toán khác nhau.
Wiki để hỏi, không phải để đọc
Một twist mình thấy rất hay trong bài của Vĩ: Karpathy không xây wiki chủ yếu để đọc lại.
Nghe hơi ngược đời đúng không?
Vì đa số chúng ta nghĩ note app là nơi lưu để sau này đọc lại. Notion, Apple Notes, Obsidian vault, bookmark folder - tất cả thường được dùng như kho chứa đồ.
Mình lưu vì sợ mất. Nhưng thú thật là rất ít khi quay lại đọc. Mình cũng từng setup Obsidian rất đẹp rồi để đó.
Wiki của Karpathy khác. Nó được xây để hỏi.
Khi hệ thống có đủ tài liệu gốc và wiki đã được xử lý, các bạn có thể hỏi những câu mà một note đơn lẻ không trả lời được:
- "So sánh cách paper A và paper B tiếp cận alignment."
- "Những gì mình đã đọc về reasoning của LLM đang gặp nhau ở điểm nào?"
- "Có nguồn nào mâu thuẫn với quan điểm mình đang tin không?"
- "Các khái niệm liên quan đến agent memory đã thay đổi thế nào trong 12 tháng qua?"
- "Nếu phải viết một bài blog từ toàn bộ nguồn đã đọc, outline tốt nhất là gì?"
Đây là khác biệt giữa kho chứa đồ và thư viện có thủ thư.
Kho chứa đồ chỉ giữ mọi thứ. Các bạn vẫn phải tự nhớ món nào nằm đâu.
Thư viện có thủ thư thì khác. Bạn hỏi một câu. Thủ thư biết tài liệu nào liên quan, nguồn nào đáng tin, chỗ nào mâu thuẫn, chỗ nào còn thiếu.
LLM trong hệ thống này đóng vai trò gần giống thủ thư. Nhưng nó chỉ giỏi khi thư viện có cấu trúc tốt.
Nếu các bạn chỉ ném link, screenshot, PDF không tên, note không ngữ cảnh vào một chỗ, thì AI cũng chỉ đang bới rác nhanh hơn mình thôi.
Vì sao Karpathy tự xây search tool
Một chi tiết nhỏ nhưng mình thấy đáng chú ý: Karpathy dùng qmd để tìm kiếm local. Nghĩa là ổng không phó mặc việc truy xuất thông tin cho một nền tảng AI hộp đen.
Vì sao chuyện này quan trọng?
Vì ai kiểm soát truy xuất thông tin thì kiểm soát chất lượng câu trả lời.
Nếu các bạn hỏi một nền tảng AI và để nó tự quyết định lấy thông tin từ đâu, các bạn đang phụ thuộc vào một lớp mình không thấy.
Nó lấy gì? Bỏ qua gì? Xếp hạng theo tiêu chí nào? Có dùng nguồn của mình không? Ưu tiên nguồn mới hay nguồn cũ? Có bị giới hạn ngữ cảnh làm mất chi tiết quan trọng không?
Một số trường hợp thì chuyện đó không sao. Nhưng với knowledge base cá nhân, nhất là thứ đại diện cho quá trình học của mình, việc truy xuất thông tin quá quan trọng để giao hết cho hộp đen.
Karpathy không nhất thiết tự viết mọi thứ vì thích khổ. Mình nghĩ ổng đang giữ quyền sở hữu ở tầng nền tảng.
File nằm trên máy. Định dạng là Markdown. Tìm kiếm chạy local. GitHub lưu lịch sử thay đổi. LLM chỉ là người phụ việc, có thể thay.
Hôm nay dùng Claude. Mai dùng GPT. Mốt dùng model local. Không sao cả. Vì lớp kiến thức không bị khóa trong app nào.
Đây là bài học lớn hơn công cụ: nguyên tắc quan trọng hơn công cụ.
First Brain trước Second Brain
Mình vừa đọc thêm một bài rất đáng suy nghĩ trên Substack của anh Goon Nguyễn. Có một câu chốt rất mạnh: hãy xây First Brain trước khi xây Second Brain.
Bài của bạn ấy có một góc nhìn mà cả gist của Karpathy lẫn bài phân tích của Vĩ chưa nhấn đủ: vấn đề kiểm chứng.
Karpathy nói LLM trong hệ thống là "librarian", còn người dùng là "curator". Nghe rất hợp lý. Nhưng có một chi tiết dễ bị bỏ qua.
Karpathy có hơn 20 năm kinh nghiệm AI để kiểm chứng đầu ra.
Khi LLM tóm tắt một paper, bịa một citation, hiểu lệch một khái niệm, ổng nhận ra rất nhanh. Phần lớn chúng ta thì không. Não mình cũng không phải loại khủng để nhìn phát biết ngay model đang xạo chỗ nào.
Ảo giác của AI không phải bug. Nó là tính năng.
Câu đó không phải mình nói, mà là anh Goon Nguyễn trích trong bài. Nhưng nó nói rất đúng bản chất LLM: model sinh ra đoạn chữ có xác suất cao nhất, không phải đoạn chữ đúng nhất.
Khi các bạn nhờ nó hệ thống hóa kiến thức mà mình chưa đủ hiểu, nó vẫn viết ra một wiki rất trôi chảy. Trôi chảy tới mức mình không nhận ra nó đang sai.
Và khi lỗi sai đó được lưu lại, được liên kết chéo, rồi được LLM đọc tiếp trong những lần hỏi sau, nó trở thành nền cho các câu trả lời tiếp theo.
Một knowledge base sai nhưng nhìn rất chuyên nghiệp còn nguy hiểm hơn một folder bookmark lộn xộn.
Bài Substack có nhắc vài nghiên cứu khá đáng chú ý: một study của Microsoft và CMU trên 319 worker, một study khác của Gerlich với 666 người, và paper "Your Brain on ChatGPT" của MIT Media Lab dùng EEG để đo hoạt động não.
Điểm chung là: càng phụ thuộc AI sớm, tư duy phản biện càng giảm. Không phải vì AI ngu. Mà vì con người ngừng động não khi có ai làm hộ.
Điều này giải thích vì sao copy y chang quy trình của Karpathy lại khá rủi ro.
Karpathy xây LLM Wiki trên nền kiến thức sẵn có của ổng. Còn nếu các bạn xây Second Brain khi First Brain chưa đủ, hệ thống rất dễ thành một cái máy chế text trơn tru cho chính mình.
Mình sẽ có cảm giác mình hiểu vấn đề vì đã có wiki. Nhưng thực tế mình chỉ đang tin vào đầu ra của một hộp đen mà mình không đủ nền để kiểm chứng.
Các bạn không thể chọn lọc thứ mà chính mình không xác minh được. Nếu chưa đủ hiểu một chủ đề, wiki do AI viết về chủ đề đó rất dễ trở thành một vòng lặp kiến thức trơn tru: đọc có vẻ đúng, nhưng không ai đủ chắc để kiểm tra.
First Brain trước Second Brain có thể bắt đầu từ vài thói quen rất đời thường.
Đọc kỹ trước khi clip. Đừng dùng Obsidian để thay cho việc đọc.
Viết tay một note trước khi nhờ AI mở rộng. Ý đầu tiên nên là của mình.
Kiểm tra nguồn. LLM bịa citation giỏi hơn mình tưởng, nên phải có thói quen mở link gốc.
Học sâu trước khi học dàn trải. Không cần 10 chủ đề song song. Một chủ đề đủ sâu đã khó rồi.
Và tuần nào cũng nên có một buổi làm việc không AI. Để biết não mình còn chạy được không.
Mình nghĩ đây là phần nối thêm rất đáng giá cho câu chuyện Karpathy. Không phải để phủ nhận LLM Wiki. Mà để nhắc rằng công cụ chỉ mạnh khi người dùng đủ nền.
Vì sao ý tưởng này viral đến vậy
Mình nghĩ có vài lý do rất dễ hiểu.
Đầu tiên là vì ai cũng từng thất bại với Second Brain. Note-taking app thì nhiều vô kể. Ai cũng từng có Notion workspace đẹp, Obsidian vault mới, folder "Learning", folder "Research", bookmark "Read later".
Nhưng không mấy ai thật sự xây được một kho kiến thức sống lâu và còn dùng được. Mình cũng từng setup xong rồi bỏ đó, nên đoạn này hơi nhột.
Gist của Karpathy cho mọi người một tia hy vọng mới: biết đâu lần này AI sẽ gánh được phần ghi chép lặt vặt tẻ nhạt.
Thứ hai, nó đến đúng thời điểm. Claude Code, Cursor, Gemini CLI, tìm kiếm local, Markdown tooling giờ đã đủ mạnh để đọc, viết, cập nhật nhiều file. Nếu cách đây vài năm thì ý tưởng này hơi xa. Bây giờ thì có thể làm thật.
Thứ ba, nó chạm đúng nỗi lo thời AI: sợ não mình nhỏ lại. Sợ đọc nhiều nhưng không giữ được gì. Sợ mỗi ngày đều có paper mới, công cụ mới, framework mới, nhưng kiến thức của mình không tích lũy được.
Và thứ tư, vẫn là vì Karpathy nói. Cùng một ý tưởng nếu một người lạ viết blog post thì có thể trôi qua. Karpathy viết thì thành movement.

Nhưng áp dụng thật thì không dễ như nghe
Đây là chỗ mình muốn nói thẳng.
Gist của Karpathy là cách làm cá nhân của một người đọc rất nhiều, có kỷ luật cao, và có nhu cầu tổng hợp kiến thức chuyên sâu.
Ổng xử lý paper, video, khóa học, ghi chú nghiên cứu, khái niệm kỹ thuật. Những thứ này thật sự cần được liên kết chéo và hệ thống hóa lại.
Còn phần lớn mọi người không có nhu cầu giống ổng.
Mình thấy nhiều bạn sau khi đọc gist sẽ muốn lao vào setup Obsidian, tạo vault mới, viết CLAUDE.md, cài Dataview, clip một đống bài. Cảm giác rất đã. Một đứa hay FOMO như mình hiểu cảm giác đó lắm.
Nhưng vài tuần sau vault nằm im. Vì không có đủ nguồn chất lượng để nạp đều. Không có câu hỏi đủ khó để cần wiki trả lời. Setup thì vui, duy trì thì chán.
Chưa kể LLM vẫn cần review. Nếu không, wiki rất dễ đầy lỗi bịa đặt, hoặc những bản tóm tắt nghe mượt nhưng nông. Bộ quy tắc chưa rõ thì AI viết mỗi file một kiểu. Và nếu mình chưa có thói quen đưa kết quả từ chat ngược lại vào kho kiến thức, mọi thứ lại rơi về chỗ cũ.
Nói cách khác: cái khó không phải là cài Obsidian. Cái khó là các bạn có thật sự cần một codebase cho kiến thức hay không.
Một Second Brain chỉ có giá trị khi bạn có đủ đầu vào để nuôi nó và có đủ câu hỏi để quay lại sử dụng nó. Nếu không, đó chỉ là một thư mục Markdown đẹp đẽ nhưng không ai mở lại.
Mình nghĩ phần lớn mọi người share gist này không phải vì đã áp dụng, mà vì thấy hay. Và thấy hay thì không có gì sai.
Nhưng nếu thấy hay rồi lao vào setup ngay vì sợ bị bỏ lại trong cuộc đua AI, thì đó là FOMO. Công cụ chỉ có giá trị khi nó thật sự giải quyết một vấn đề đang tồn tại.
Khi nào thì nên áp dụng
Theo mình, cách làm này phù hợp với một nhóm nhỏ. Nhưng nếu đúng người, nó sẽ rất có giá trị.
Ví dụ như người làm research, đọc nhiều paper, cần so sánh và tổng hợp liên tục. Content creator, blogger, YouTuber, newsletter writer cần gom nhiều nguồn thành quan điểm riêng.
Engineer senior làm trên hệ thống lớn cũng có thể dùng để lưu quyết định kiến trúc, trade-off, sự cố, quy ước kỹ thuật. Founder hoặc product builder thì có thể theo dõi thị trường, insight khách hàng, đối thủ, hướng phát triển kỹ thuật.
Hoặc đơn giản là một người đang học một lĩnh vực mới đủ nghiêm túc, muốn xây mô hình tư duy dài hạn thay vì đọc xong rồi quên.
Nếu các bạn chỉ thỉnh thoảng đọc bài, thỉnh thoảng ghi chú, thì Apple Notes, Notion, hoặc một folder Markdown đơn giản đã đủ. Không cần dựng cả pipeline nạp nguồn - hỏi wiki - rà soát định kỳ.
Nhưng nếu các bạn thường xuyên có cảm giác "mình đã đọc cái này ở đâu rồi", "mấy nguồn này có vẻ mâu thuẫn", "mình cần tổng hợp toàn bộ hiểu biết về chủ đề này", thì LLM Wiki bắt đầu có ý nghĩa.
Nguyên tắc quan trọng hơn công cụ
Nếu chỉ copy công cụ của Karpathy, các bạn rất dễ bỏ cuộc. Vì bộ công cụ của ổng sinh ra từ nhu cầu của ổng, không chắc hợp với mình.
Thứ nên lấy là nguyên tắc.
Làm chủ nền tảng kiến thức của mình: nền tảng là folder trên máy hoặc GitHub. App chỉ là giao diện.
Tách tài liệu gốc và phần đã xử lý: tài liệu gốc không sửa. Wiki là lớp kiến thức đã được chắt lọc.
Làm cho kiến thức có thể hỏi được: đừng chỉ lưu để đọc lại. Lưu để hỏi được câu hỏi tốt hơn.
Để AI làm phần ghi chép lặt vặt: để AI lo cập nhật link, tóm tắt, tạo index, thêm metadata, kiểm tra mâu thuẫn. Đây là phần con người hay bỏ cuộc.
Con người quyết định chất lượng nguồn: AI có thể hệ thống hóa, nhưng các bạn phải chọn nguyên liệu và review kết quả.
Rà soát kiến thức định kỳ: tìm mâu thuẫn, nhận định đã cũ, khoảng trống, trang mồ côi.
Nếu hiểu mấy nguyên tắc này, các bạn có thể làm rất nhẹ. Không cần giống Karpathy.
Một phiên bản tối giản có thể chỉ là:
- Tạo một folder
knowledge/trên máy hoặc GitHub. - Tạo
raw/để lưu bài viết, PDF, transcript, ghi chú thô. - Tạo
wiki/để lưu Markdown đã xử lý. - Tạo một file rule như
AGENTS.mdhoặcCLAUDE.mdmô tả cách AI phải nạp nguồn và cập nhật wiki. - Mỗi tuần chọn vài nguồn tốt, nhờ AI hệ thống hóa vào wiki, rồi tự review.
Chỉ vậy thôi. Đừng bắt đầu bằng 15 plugin.
Góc nhìn của mình từ Knowns
Mình cũng đang build một CLI tool tên là Knowns, một layer Memory cho một hoặc nhiều dự án. Nên khi đọc gist của Karpathy, mình thấy đồng cảm khá nhiều.
Lý do mình làm Knowns cũng giống câu chuyện của Karpathy ở một điểm: mỗi khi muốn AI hiểu task đang làm, mình phải tự gõ lại context, giải thích lại mọi thứ. Làm hoài cũng mệt. Nên mình muốn một nơi mà mình gõ @doc/architecture hay @task-123 là AI tự đọc, tự hiểu, không cần giải thích lại mỗi phiên làm việc mới.
Ý tưởng chung giữa Knowns và LLM Wiki khá giống: dùng Markdown có cấu trúc làm bộ nhớ, để cả người và AI đều đọc, viết, duy trì được.
Khác nhau ở phạm vi. LLM Wiki của Karpathy xoay quanh kiến thức cá nhân: paper, khái niệm, lộ trình học. Còn Knowns xoay quanh ngữ cảnh của một codebase và cả team: task, doc, spec, quyết định, quy ước, template.
Nhưng bài học chung rất rõ: phần ghi chép lặt vặt là rào cản lớn nhất. Không ai đủ kiên nhẫn để tự tay liên kết chéo, đồng bộ task, ghi log, nhớ context. AI nên gánh phần đó trong lúc mình làm việc thật.
Một điểm nữa mình thấy rất trùng: bộ quy tắc quan trọng hơn UI. Nếu AI không biết quy ước, không biết file nào là nguồn chuẩn, không biết khi nào phải cập nhật task hay doc, thì nó chỉ viết thêm text. Muốn AI trở thành cộng sự, knowledge base phải có rule.
Nếu anh em đang cần một layer Memory cho dự án của mình, có thể thử Knowns tại Knowns.sh. Mình sẽ viết một bài chi tiết hơn về Knowns sau. Một star ⭐ cũng là động lực lớn cho mình tiếp tục phát triển project.
Markdown có cấu trúc - đủ đơn giản cho người, đủ rõ ràng cho AI. Làm chủ nền
tảng kiến thức, còn công cụ thì có thể thay.
Nếu muốn thử, bắt đầu như thế nào
Mình nghĩ cách tốt nhất là thử nhỏ trong 2 tuần. Đừng setup quá nhiều ngay từ đầu.
- Tạo đất của bạn: một folder local hoặc GitHub repo. Đừng bắt đầu trong app đóng. Folder mới là nền tảng.
- Ném tài liệu vào
raw/: bài viết, PDF, transcript, note thô. Ưu tiên nguồn bạn thật sự muốn học, không phải link lưu vì sợ bỏ lỡ. - Dùng AI xử lý sang
wiki/: yêu cầu AI tóm tắt, giải thích khái niệm, link đến note liên quan, ghi câu hỏi mở. - Hỏi wiki, không hỏi từng file: đặt câu hỏi tổng hợp, so sánh, mâu thuẫn, khoảng trống. Nếu câu trả lời hay, lưu ngược lại vào wiki.
- Rà soát mỗi tuần: nhờ AI tìm nhận định đã cũ, note trùng, mâu thuẫn, trang không liên kết tới đâu, khái niệm thiếu định nghĩa.
Sau 2 tuần, tự hỏi: mình có quay lại hỏi nó không?
Nếu không, dừng. Không sao cả. Ít nhất các bạn đã học được nguyên tắc.
Kết luận
Gist của Karpathy đáng đọc. Không phải vì nó cho mình một công thức hoàn hảo để copy. Mà vì nó nói rất rõ một hướng đi mới: AI không chỉ là chatbot trả lời tức thời, mà có thể là người phụ việc giúp duy trì một codebase kiến thức cho mình.
Nhưng mình không nghĩ mọi người đều cần làm theo. Nếu chỉ vì thấy Karpathy làm nên mình cũng làm, rất dễ biến nó thành một màn diễn năng suất khác.
Trước khi setup vault mới, mình nghĩ nên tự hỏi 4 câu:
- Mình có vấn đề thật nào cần một kho kiến thức dài hạn giải quyết không?
- Mình muốn dùng AI để suy nghĩ ngắn hạn, hay để xây kiến thức dài hạn?
- Mình có sẵn sàng sở hữu folder, nguồn, bộ quy tắc, và tự review kết quả không?
- Mình đã có đủ First Brain ở chủ đề này để kiểm chứng những gì AI viết ra chưa?
Nếu câu trả lời là có, hãy thử. Nếu không, đừng FOMO. Một note app đơn giản cộng với thói quen đọc kỹ vẫn tốt hơn một bộ não ngoài bỏ hoang.
Nguyên tắc đáng học nhất từ Karpathy không phải là Obsidian, qmd, Dataview hay Marp. Nguyên tắc là: sở hữu kiến thức của mình, cấu trúc nó đủ tốt để hỏi, và để AI làm phần duy trì mà con người hay bỏ cuộc.
See yah.
Nguồn tham khảo
- Gist gốc của Karpathy: LLM Wiki Gist
- Bài phân tích của Vĩ, Facebook Mod Nghiện AI, trên Facebook. Một số insight trong bài này được tổng hợp và paraphrase từ bài phân tích đó, đặc biệt là ẩn dụ kiến thức như codebase, phân biệt AI để suy nghĩ và AI để xây kiến thức, và ý tưởng wiki để hỏi thay vì chỉ để đọc.
- Bài Hướng dẫn xây dựng Second Brain hiệu quả của anh Goon Nguyễn trên Substack. Góc nhìn về "First Brain trước Second Brain", vấn đề kiểm chứng, và các nghiên cứu về ảnh hưởng của AI đến tư duy phản biện được tham khảo từ bài này.
- Khái niệm Second Brain: Tiago Forte, Building a Second Brain