Karpathy's Second Brain - actually useful or just FOMO?
Karpathy's LLM Wiki gist went viral. I took a closer look: what's genuinely good, who should apply it, and how to avoid FOMO.
May 12, 2026 · 21 min read
The past few days I've seen Twitter, Reddit, Hacker News, and even Vietnamese dev groups all talking about a gist by Andrej Karpathy. It's about how he built a personal wiki using LLMs to manage knowledge. Many people are calling it "Karpathy's Second Brain."
I was curious so I read the original gist. Then read further analysis from Vi (Mod Nghien AI) on Facebook and a piece by Goon Nguyen on Substack.
Each gave me a different angle. Vi talked brilliantly about treating knowledge like a codebase. Goon Nguyen asked harder questions about verification, especially when your "real brain" isn't solid enough yet.
Karpathy's idea is genuinely good. But I don't want to write a fanboy post saying "everyone must do this immediately."
I want to ask more directly:
Are people actually understanding and applying this, or just FOMO-ing because Karpathy said it?
In the gist, Karpathy doesn't call this system "Second Brain." He calls it an LLM-maintained wiki or exocortex. "Second Brain" is a concept popularized by Tiago Forte earlier. The two overlap but aren't identical. I'm using "Second Brain" here because that's what the community is calling Karpathy's system.
Why Karpathy's words carry so much weight
For those who don't know, Karpathy is one of the biggest names in AI. He was Director of AI at Tesla, co-founder of OpenAI, and taught CS231n at Stanford — one of the most famous deep learning courses.
Recently he's been making very polished educational videos about LLMs, tokenizers, backpropagation, neural networks. The kind of videos that technical people love because everything is explained clearly without fluff.
In short: when Karpathy posts something, the community listens.
Not just because he's brilliant. But because he rarely speaks in marketing-speak. He tends to look at everything as a system: inputs, outputs, state, loops, failure points, supporting tools.
So when he talks about how to learn, take notes, or use AI, people don't see it as a fun productivity hack. It feels like a process that a very capable person has actually been using for real.
That's why even a fairly short gist created waves. Not because the idea is entirely new. Obsidian, Zettelkasten, PARA, RAG, personal wikis — all existed before.
But when Karpathy combines them into a working system, the community sees a more credible version.

Karpathy's LLM Wiki — short summary
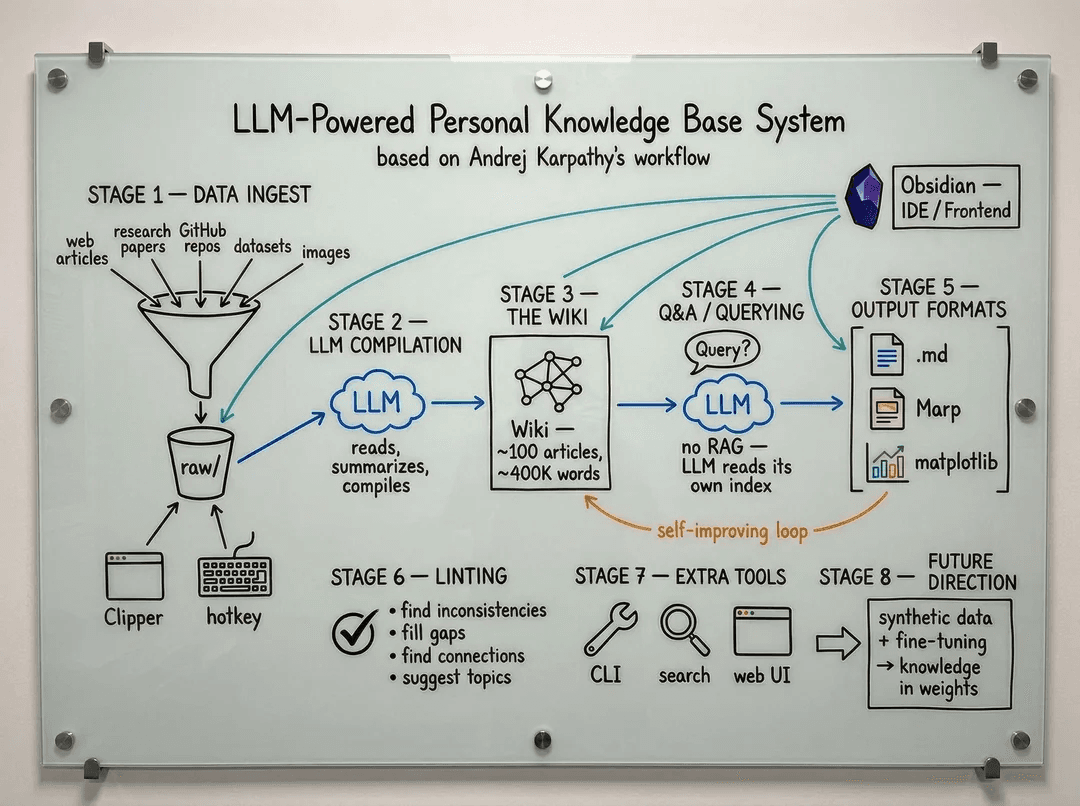
Reading the gist carefully, Karpathy's approach is quite clear. No fluff. No new app needed. No complex database.
The foundation is just a folder on his machine, Markdown, GitHub, and an LLM.
He doesn't want to use RAG in the traditional sense: querying raw documents each time, stuffing context into a prompt, letting the model synthesize from scratch. That's useful, but it doesn't create accumulated knowledge. Each query is almost starting over.
Karpathy wants to build a wiki with accumulation. Meaning the LLM doesn't just answer questions. It also maintains a layer of processed, linked, updated knowledge.
Next time you ask, you ask against that wiki layer. Not always going back to the raw documents.
The structure has 3 layers:
- Source documents: original materials — papers, articles, code, transcripts, images, raw notes. These are ingredients. Kept intact, never modified.
- Wiki: processed Markdown files. Summaries, concept pages, person/org pages, cross-links, observations, contradictions, open questions.
- Ruleset: files like
CLAUDE.mdorAGENTS.md, defining conventions, operations, naming, updating rules, how the LLM should behave.
The workflow revolves around 3 main operations.
Ingest means bringing in new documents. The LLM reads, summarizes, updates related pages, adds links, logs changes.
Query the wiki means asking questions against the processed knowledge layer. Not just "summarize this article," but questions that require synthesizing multiple sources.
Audit the wiki means periodic review. Finding contradictions, outdated observations, orphan pages, knowledge gaps, broken links.
Tools are very everyday: Obsidian for reading and editing the wiki, Obsidian Web Clipper for saving articles, qmd for local search, Dataview for querying metadata, Marp for making slides.
But the important point isn't the tool names. The important point is the structure: source documents in one place, processed knowledge in another, operating rules in another.
Knowledge as a codebase
This is the insight I liked most from Vi's analysis.
Karpathy is an engineer, so he looks at knowledge the way engineers look at a codebase. An unmaintained codebase rots gradually. Stale dependencies. Inconsistent naming. Duplicated logic. Wrong comments. Modules nobody dares touch.
Bugs don't show up immediately. But quality degrades bit by bit.
Personal knowledge works the same way.
You might read a lot. But if that knowledge isn't linked, checked, and updated, it becomes a pile of disconnected files.
Some things were true when you read them but wrong now. Some things contradict each other and you don't know. Some important things are buried in bookmarks, PDFs, screenshots, chat history.
Sound familiar? It does to me.
Your brain today, if not properly nourished, might be worse than your brain 6 months ago.
That sounds a bit painful, but I think it's true. Not because we forget everything. But because the environment changes faster than our self-update speed.
In AI, a paper from 6 months ago might already be outdated. A best practice from last year might be an anti-pattern now. A belief you once held might need revisiting.
If you view knowledge as a codebase, the questions change.
You don't just ask "have I saved this?" You ask: which parts of my knowledge are stale? Are any notes contradicting each other? Are there concepts I use constantly but haven't clearly defined? Are there sources I trust too much without cross-referencing? Are there scattered notes that should be consolidated into a clearer mental model?
This is what makes LLM Wiki different from regular note-taking. It doesn't just store. It also maintains.
AI for thinking vs AI for building knowledge
This is something I think few people notice, but it's important.
Most people use AI like this: open ChatGPT or Claude, throw in a question, get an answer, tweak it a few rounds until satisfied, close the tab. I do this too.
That's using AI for short-term thinking.
It's very useful. I use it daily. But it's more like RAM than a hard drive. It helps me in a single work session.
If you don't save it, restructure it, feed it back into your system, it's basically gone in a few days.
Karpathy's LLM Wiki goes a different direction: using AI to accumulate and systematize long-term knowledge.
The difference is in the end result.
Regular chat produces answers within a session. Wiki produces Markdown files that can live long in your directory.
Chat helps you handle the current question. Wiki helps you accumulate context for future questions.
Chat depends on a platform. Wiki lives on your machine, on your GitHub, readable by any editor.
According to community discussions, after a year Karpathy's wiki has about 100 articles and hundreds of thousands of words. Even if OpenAI, Anthropic, Notion, or any app changes their policy, that Markdown folder remains.
This is the part many people miss when FOMO-ing. They think the main point is "using AI to take notes faster."
But the deeper point is: using AI to turn learning into a system with memory and accumulation.
Chatting with AI is short-term memory. A wiki maintained by AI is long-term memory. Both are useful, but they solve different problems.
Wiki for asking, not for reading
A twist I found really clever from Vi's analysis: Karpathy doesn't build the wiki primarily to read back.
Sounds counterintuitive, right?
Because most of us think note apps are places to save things for later reading. Notion, Apple Notes, Obsidian vault, bookmark folders — all typically used as storage.
We save because we're afraid of losing things. But honestly, we rarely go back to read. I've also set up Obsidian beautifully and then just left it there.
Karpathy's wiki is different. It's built to ask.
When the system has enough source documents and processed wiki, you can ask questions that a single note can't answer:
- "Compare how paper A and paper B approach alignment."
- "Where do the things I've read about LLM reasoning converge?"
- "Are there any sources contradicting a belief I currently hold?"
- "How have concepts related to agent memory changed over the past 12 months?"
- "If I had to write a blog post from all sources I've read, what's the best outline?"
This is the difference between a storage room and a library with a librarian.
A storage room just keeps everything. You still have to remember where each thing is.
A library with a librarian is different. You ask a question. The librarian knows which documents are relevant, which sources are trustworthy, where contradictions exist, where gaps remain.
The LLM in this system plays a role close to a librarian. But it's only good when the library is well-structured.
If you just throw in links, screenshots, unnamed PDFs, notes without context — then AI is just sifting through garbage faster.
Why Karpathy builds his own search tool
A small detail I found noteworthy: Karpathy uses qmd for local search. Meaning he doesn't hand over information retrieval to a black-box AI platform.
Why does this matter?
Because whoever controls information retrieval controls the quality of answers.
If you ask an AI platform and let it decide where to pull information from, you're depending on a layer you can't see.
What does it retrieve? What does it skip? What ranking criteria? Does it use your sources? Does it prioritize new or old? Does context limits cause it to lose important details?
In some cases that's fine. But for a personal knowledge base — especially one representing your learning journey — information retrieval is too important to hand entirely to a black box.
Karpathy doesn't necessarily build everything himself because he enjoys suffering. I think he's maintaining ownership at the foundational layer.
Files live on his machine. Format is Markdown. Search runs locally. GitHub stores change history. The LLM is just an assistant that can be replaced.
Today use Claude. Tomorrow use GPT. Next week use a local model. No problem. Because the knowledge layer isn't locked into any app.
This is a lesson bigger than tools: principles matter more than tools.
First Brain before Second Brain
I also read a very thought-provoking piece on Goon Nguyen's Substack. There's one killer line: build your First Brain before building your Second Brain.
His piece has an angle that neither Karpathy's gist nor Vi's analysis emphasized enough: the problem of verification.
Karpathy says the LLM in the system is a "librarian" and the user is a "curator." Sounds very reasonable. But there's an easily overlooked detail.
Karpathy has 20+ years of AI experience to verify outputs.
When the LLM summarizes a paper, fabricates a citation, misinterprets a concept — he catches it quickly. Most of us don't. Our brains aren't the kind that can instantly spot where the model is bullshitting.
AI hallucination isn't a bug. It's a feature.
That's not my line — Goon Nguyen quoted it in his piece. But it captures the nature of LLMs perfectly: the model generates text with the highest probability, not the highest accuracy.
When you ask it to systematize knowledge you don't yet understand well, it still produces a very fluent wiki. So fluent you don't realize it's wrong.
And when that error gets saved, cross-linked, then read by the LLM in future queries, it becomes the foundation for subsequent answers.
A knowledge base that's wrong but looks professional is more dangerous than a messy bookmark folder.
The Substack piece mentions some notable research: a Microsoft and CMU study on 319 workers, another by Gerlich with 666 participants, and the "Your Brain on ChatGPT" paper from MIT Media Lab using EEG to measure brain activity.
The common finding: the earlier you depend on AI, the more critical thinking declines. Not because AI is dumb. But because humans stop thinking when someone else does it for them.
This explains why copying Karpathy's process exactly is quite risky.
Karpathy built LLM Wiki on top of his existing knowledge. If you build a Second Brain when your First Brain isn't ready, the system easily becomes a machine generating smooth text for yourself.
You'll feel like you understand a topic because you have a wiki. But in reality you're just trusting the output of a black box that you don't have enough foundation to verify.
You can't curate what you can't verify. If you don't understand a topic well enough, a wiki written by AI about that topic easily becomes a smooth knowledge loop: reads like it's correct, but nobody's sure enough to check.
First Brain before Second Brain can start with very everyday habits.
Read carefully before clipping. Don't use Obsidian as a substitute for reading.
Write a note by hand before asking AI to expand it. The first idea should be yours.
Check sources. LLMs fabricate citations better than you'd think — build the habit of opening original links.
Go deep before going wide. You don't need 10 topics in parallel. One topic deep enough is already hard.
And every week, have one work session without AI. To know if your brain still runs on its own.
I think this is a very valuable addition to the Karpathy story. Not to dismiss LLM Wiki. But to remind that tools are only powerful when the user has enough foundation.
Why this idea went so viral
I think there are a few very understandable reasons.
First, everyone has failed at Second Brain before. Note-taking apps are countless. Everyone has had a beautiful Notion workspace, a fresh Obsidian vault, a "Learning" folder, a "Research" folder, a "Read later" bookmark collection.
But very few actually build a knowledge base that lives long and remains usable. I've also set things up beautifully and then abandoned them, so this part stings a bit.
Karpathy's gist gives people new hope: maybe this time AI can carry the tedious note-keeping part.
Second, it arrived at the right moment. Claude Code, Cursor, Gemini CLI, local search, Markdown tooling are now powerful enough to read, write, and update many files. A few years ago this idea would've been too far-fetched. Now it's doable.
Third, it hits the exact AI-era anxiety: fear that your brain is shrinking. Fear of reading a lot but retaining nothing. Fear that every day brings new papers, new tools, new frameworks, but your knowledge doesn't accumulate.
And fourth, it's still because Karpathy said it. The same idea from a stranger's blog post might float by unnoticed. Karpathy writes it and it becomes a movement.

But actually applying it isn't as easy as it sounds
This is where I want to be direct.
Karpathy's gist is the personal workflow of someone who reads extensively, has high discipline, and has a genuine need for deep knowledge synthesis.
He processes papers, videos, courses, research notes, technical concepts. These things genuinely need cross-linking and systematization.
Most people don't have the same needs.
I see many people after reading the gist wanting to rush into setting up Obsidian, creating a new vault, writing CLAUDE.md, installing Dataview, clipping a ton of articles. Feels great. As someone prone to FOMO, I totally get that feeling.
But a few weeks later the vault sits idle. Because there aren't enough quality sources to feed it regularly. There aren't questions hard enough to need a wiki to answer. Setup is fun, maintenance is boring.
Not to mention LLMs still need review. Without it, the wiki easily fills with fabrications, or summaries that sound smooth but are shallow. If the ruleset isn't clear, AI writes each file differently. And if you don't have the habit of feeding chat results back into your knowledge base, everything falls back to where it started.
In other words: the hard part isn't installing Obsidian. The hard part is whether you actually need a codebase for your knowledge.
A Second Brain only has value when you have enough input to feed it and enough questions to come back and use it. Otherwise, it's just a beautiful Markdown folder that nobody reopens.
I think most people sharing this gist aren't doing so because they've applied it, but because they found it interesting. And finding it interesting is perfectly fine.
But if you find it interesting and rush to set up immediately because you're afraid of being left behind in the AI race — that's FOMO. Tools only have value when they actually solve an existing problem.
When should you apply this
In my view, this approach fits a small group. But for the right person, it's very valuable.
For example, researchers who read many papers and need to compare and synthesize continuously. Content creators — bloggers, YouTubers, newsletter writers — who need to combine many sources into their own perspective.
Senior engineers working on large systems could use it to store architecture decisions, trade-offs, incidents, technical conventions. Founders or product builders could track markets, customer insights, competitors, technical direction.
Or simply someone learning a new field seriously enough, wanting to build a long-term mental model rather than reading and forgetting.
If you only occasionally read articles, occasionally take notes, then Apple Notes, Notion, or a simple Markdown folder is enough. No need to build an entire ingest-query-audit pipeline.
But if you frequently feel "I've read this somewhere before," "these sources seem to contradict each other," "I need to synthesize everything I know about this topic" — then LLM Wiki starts making sense.
Principles matter more than tools
If you only copy Karpathy's tools, you'll likely give up. Because his toolset was born from his needs, not necessarily yours.
What you should take are the principles.
Own your knowledge foundation: the foundation is a folder on your machine or GitHub. Apps are just interfaces.
Separate source documents from processed material: source documents stay untouched. Wiki is the distilled knowledge layer.
Make knowledge queryable: don't just save to read later. Save so you can ask better questions.
Let AI handle the tedious bookkeeping: let AI handle updating links, summarizing, creating indexes, adding metadata, checking contradictions. This is where humans tend to give up.
Humans decide source quality: AI can systematize, but you must choose the ingredients and review the results.
Audit knowledge periodically: find contradictions, outdated observations, gaps, orphan pages.
If you understand these principles, you can start very light. No need to be like Karpathy.
A minimal version could just be:
- Create a
knowledge/folder on your machine or GitHub. - Create
raw/for articles, PDFs, transcripts, raw notes. - Create
wiki/for processed Markdown. - Create a rule file like
AGENTS.mdorCLAUDE.mddescribing how AI should ingest and update the wiki. - Each week pick a few good sources, ask AI to systematize them into the wiki, then review yourself.
That's it. Don't start with 15 plugins.
My perspective from Knowns
I'm also building a CLI tool called Knowns — a memory layer for one or more projects. So when I read Karpathy's gist, I felt quite a lot of resonance.
The reason I'm building Knowns is similar to Karpathy's story at one point: every time I wanted AI to understand the current task, I had to manually re-type context, re-explain everything. Gets tiring. So I wanted a place where I type @doc/architecture or @task-123 and AI reads it, understands it, no re-explanation needed each new session.
The shared idea between Knowns and LLM Wiki is quite similar: use structured Markdown as memory, so both humans and AI can read, write, and maintain it.
The difference is scope. Karpathy's LLM Wiki revolves around personal knowledge: papers, concepts, learning paths. Knowns revolves around codebase context and team: tasks, docs, specs, decisions, conventions, templates.
But the shared lesson is very clear: tedious bookkeeping is the biggest barrier. Nobody has enough patience to manually cross-link, sync tasks, log things, remember context. AI should carry that part while we do the real work.
One more point I find very aligned: the ruleset matters more than the UI. If AI doesn't know conventions, doesn't know which file is the canonical source, doesn't know when to update a task or doc, then it's just generating more text. For AI to become a collaborator, the knowledge base needs rules.
If you need a memory layer for your projects, you can check out Knowns at Knowns.sh. I'll write a more detailed post about Knowns soon. A star on GitHub is great motivation for me to keep developing the project.

If you want to try, how to start
I think the best way is to try small for 2 weeks. Don't over-setup from the start.
- Create your ground: a local folder or GitHub repo. Don't start inside a closed app. The folder is the foundation.
- Throw documents into
raw/: articles, PDFs, transcripts, raw notes. Prioritize sources you genuinely want to learn from, not links saved out of fear of missing out. - Use AI to process into
wiki/: ask AI to summarize, explain concepts, link to related notes, record open questions. - Ask the wiki, not individual files: ask synthesis questions, comparisons, contradictions, gaps. If the answer is good, save it back into the wiki.
- Audit weekly: ask AI to find outdated observations, duplicate notes, contradictions, unlinked pages, undefined concepts.
After 2 weeks, ask yourself: do I come back to ask it questions?
If not, stop. That's fine. At least you've learned the principles.
Conclusion
Karpathy's gist is worth reading. Not because it gives a perfect formula to copy. But because it clearly articulates a new direction: AI isn't just a chatbot for instant answers — it can be an assistant helping maintain a knowledge codebase for you.
But I don't think everyone needs to follow along. If you're doing it just because Karpathy did, it's very easy to turn it into another productivity theater performance.
Before setting up a new vault, I think you should ask yourself 4 questions:
- Do I have a real problem that needs a long-term knowledge base to solve?
- Do I want to use AI for short-term thinking, or for building long-term knowledge?
- Am I ready to own the folder, sources, ruleset, and review results myself?
- Do I have enough First Brain in this topic to verify what AI writes?
If the answer is yes, try it. If not, don't FOMO. A simple note app plus the habit of reading carefully is still better than an abandoned exocortex.
The most valuable principle from Karpathy isn't Obsidian, qmd, Dataview, or Marp. The principle is: own your knowledge, structure it well enough to query, and let AI handle the maintenance that humans tend to abandon.
See yah.
References
- Karpathy's original gist: LLM Wiki Gist
- Vi's analysis (Mod Nghien AI) on Facebook. Some insights in this post are synthesized and paraphrased from that analysis, particularly the knowledge-as-codebase metaphor, the distinction between AI for thinking and AI for building knowledge, and the idea of wiki for asking rather than just reading.
- Goon Nguyen's piece Guide to Building an Effective Second Brain on Substack. The "First Brain before Second Brain" perspective, verification issues, and research on AI's impact on critical thinking are referenced from this piece.
- Second Brain concept: Tiago Forte, Building a Second Brain


