
Kết hợp Opus + GPT trong Claude Code bằng Router và Sub-agent
Cách mình dùng Router để Opus giám sát tổng, GPT chạy việc nhỏ - tiết kiệm chi phí, giữ mạch tốt hơn, và xử lý feature lớn mượt hơn.
May 19, 2026 · 20 min read
Mấy hôm trước mình có share nhanh một tip trên Facebook về việc dùng 9Router để kết hợp Opus và GPT trong Claude Code. Bài đó hơi dạng note ngắn, kiểu "mình đang dùng như vầy thấy ổn nè". Không ngờ nhiều anh em hỏi thêm phần setup và cách chia nhiệm vụ.
Câu hỏi lặp lại nhiều nhất là:
- 9Router đóng vai trò gì?
- Cài thế nào để Claude Code dùng được Opus qua 9Router?
- Kiro, Claude Code, Codex/GPT nằm ở đâu trong flow?
- Chia task cho Opus và GPT sub-agent như thế nào để không loạn?
Bài này mình viết lại chi tiết hơn. Vừa là cách mình setup, vừa là cách mình nghĩ về workflow supervisor / sub-agent khi làm project thật.
Đây không phải "cách đúng duy nhất". Đây là workflow mình đang dùng và thấy hợp với kiểu làm feature lớn, nhiều bước, cần giữ context và kiểm soát chi phí.
Vấn đề: để một model làm hết thì hơi phí
Trước đây mình hay dùng một model mạnh cho toàn bộ flow.
Một task kiểu:
"Implement feature X, đọc codebase, lên plan, sửa code, chạy test, fix lỗi, review lại."
Nghe tiện. Một model làm hết từ đầu tới cuối. Nhưng dùng một thời gian thì mình thấy vài vấn đề khá rõ.
Đầu tiên là tốn credit.
Model mạnh như Opus rất hợp để suy nghĩ, phân tích, giữ context, phát hiện hướng sai. Nhưng nếu bắt nó làm hết mấy task lặp lại kiểu rename file, thêm test case, sửa type, update import, chạy lint rồi fix format thì hơi phí.
Thứ hai là task lớn dễ trôi context.
Một model dù mạnh tới đâu, khi conversation dài lên, nhiều file được đọc, nhiều quyết định nhỏ xuất hiện, thì flow vẫn có khả năng bị loãng. Nó có thể nhớ phần đầu, quên một constraint ở giữa, hoặc đang implement thì bị cuốn vào chi tiết.
Thứ ba là tốc độ.
Có những phần không cần "suy nghĩ sâu". Chỉ cần chạy nhanh, chính xác, bám theo chỉ dẫn. Nếu dùng model nhanh hơn cho phần đó thì workflow mượt hơn nhiều.
Vậy nên mình bắt đầu tách vai trò:
- Opus: planner, supervisor, reviewer, context owner.
- GPT sub-agent: executor cho các task nhỏ, rõ scope, có input/output cụ thể.
Không phải model nào cũng nên làm mọi việc. Model mạnh nhất nên giữ vai trò cần suy luận mạnh nhất.
Router là gì? Tại sao cần?
Hiểu đơn giản, router (hay proxy) là một lớp trung gian giúp mình dùng nhiều model/provider phía sau qua một endpoint tương thích.
Trong workflow này, router giúp mình gom nhiều model vào một chỗ để Claude Code hoặc tool tương thích OpenAI/Anthropic có thể gọi model theo tên route.
Mình đang dùng 9Router, nhưng bạn hoàn toàn có thể dùng tool khác:
- 9Router - cái mình đang dùng
- OmniRoute
- CLI API Proxy
- Hoặc bất kỳ proxy nào expose được endpoint tương thích Anthropic/OpenAI
Ý tưởng đều giống nhau: gom nhiều provider vào một endpoint, rồi route theo tên model.
Ví dụ mình có thể có các route kiểu:
opus-4.6trỏ tới Opus trên Kiro.gpt-5.5trỏ tới GPT-5.5.
Tên route cụ thể tuỳ bạn đặt. Ý chính là router đứng giữa:
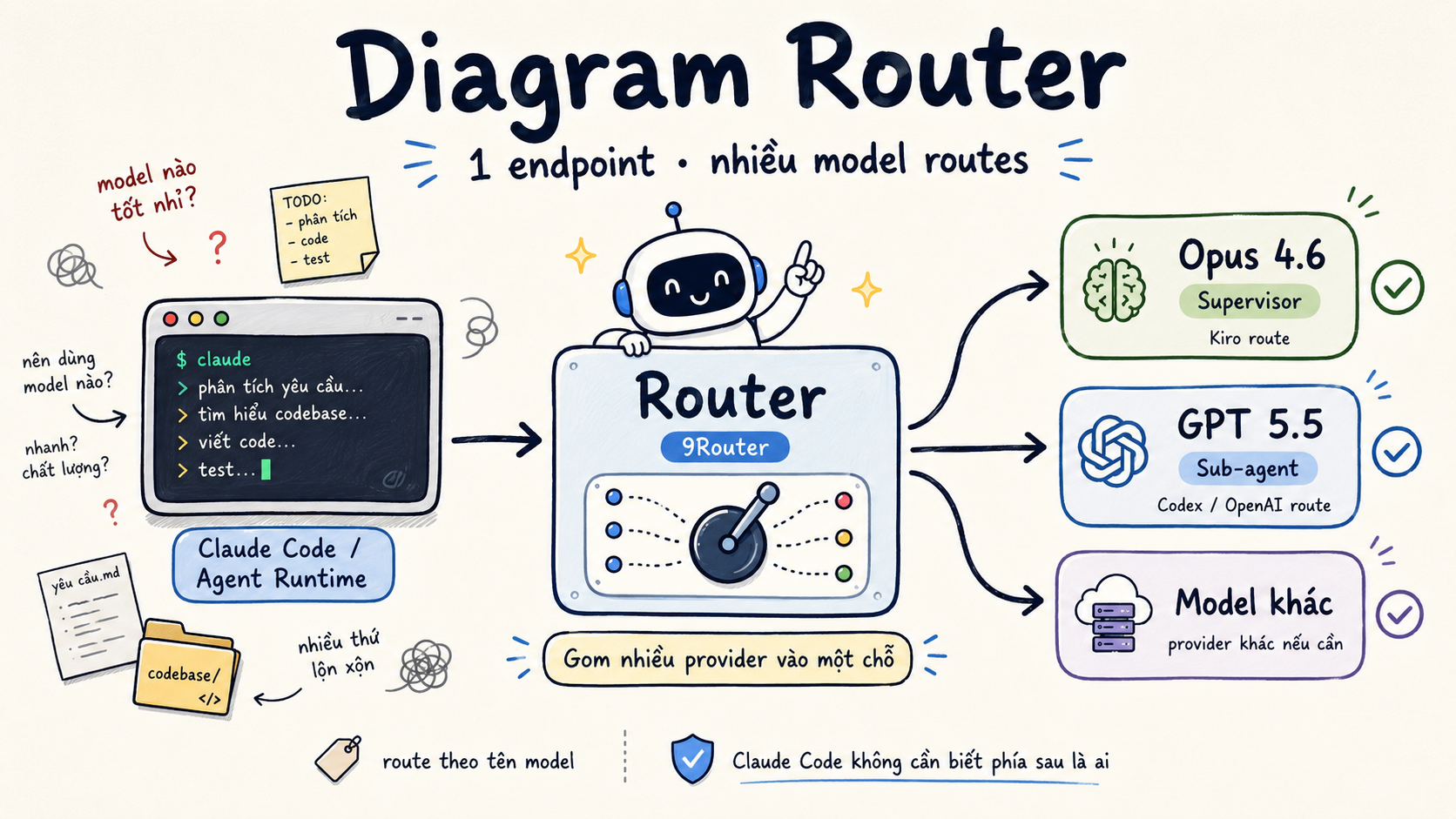
Mình hay nghĩ router giống một cái "tổng đài chuyển mạch". Claude Code không cần quan tâm phía sau model đến từ đâu. Mình chỉ cần gọi đúng route/model name, còn router lo chuyển sang provider tương ứng.
Nếu bạn đang bị lỗi "không dùng được Opus trên router cho Claude Code", thường vấn đề nằm ở model name, endpoint, auth header, hoặc route chưa được map đúng trong router của bạn.
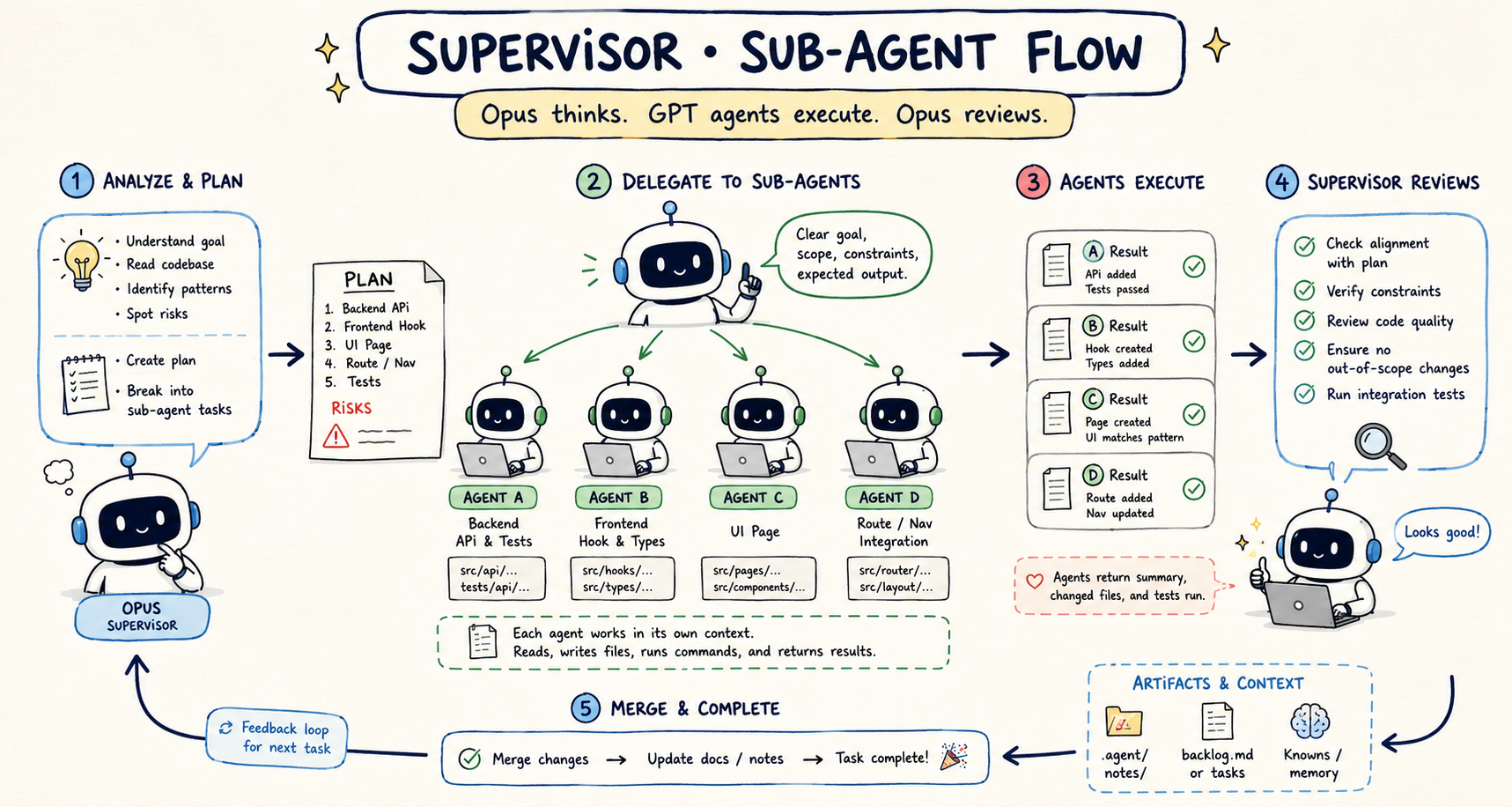
Mô hình supervisor / sub-agent
Mô hình mình dùng khá đơn giản.
Opus không trực tiếp cày hết mọi việc. Opus làm vai trò supervisor:
- đọc yêu cầu lớn
- hiểu codebase
- hỏi lại nếu thiếu
- chia task
- quyết định task nào giao cho sub-agent
- review output
- giữ context tổng
- phát hiện khi agent đi lệch
GPT sub-agent làm vai trò executor:
- nhận task nhỏ
- đọc file liên quan
- implement đúng scope
- trả lại summary
- không tự mở rộng phạm vi
- không tự quyết định architecture lớn
Nói nôm na:
Điểm quan trọng là sub-agent phải được giao task có biên rõ. Nếu giao kiểu "làm feature này đi", nó sẽ phải tự plan lại, dễ lệch khỏi ý supervisor. Còn nếu giao kiểu "sửa 3 file này, theo contract này, không đổi public API", output ổn hơn nhiều.
Cách setup tổng quan
Mình mô tả theo hướng tổng quát vì mỗi máy và mỗi account/provider có thể khác nhau. Nhưng flow chính sẽ như vầy.
Bước 1: Chuẩn bị route trên router
Trong router của bạn, cần tạo hoặc kiểm tra route cho từng model mình muốn dùng.
Ví dụ:
Tên route không nhất thiết giống ví dụ. Nhưng mình khuyên đặt tên dễ hiểu, vì lát nữa bạn sẽ dùng trong config hoặc prompt.
Nếu bạn dùng 9Router, flow setup trong giao diện sẽ như sau:
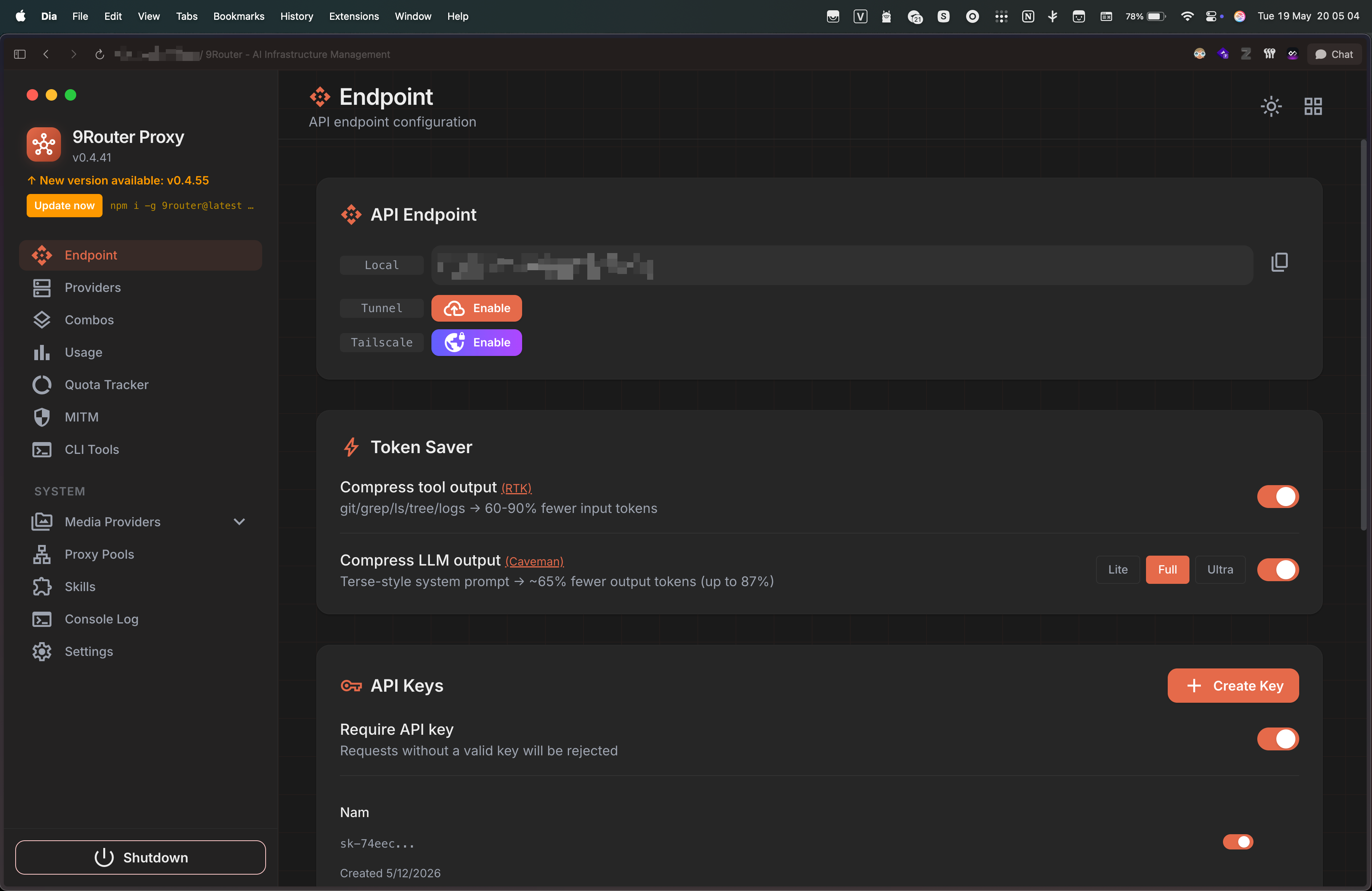
Nếu chạy local: bấm Apply là xong, 9Router tự ghi vào settings.json cho bạn. Nếu chạy trên server: chọn Manual config rồi copy config về máy server.
Đừng paste API key vào blog, repo, issue, hay prompt public. Config local nên để trong env var hoặc file local đã được gitignore.
Bước 2: Trỏ Claude Code về router
Claude Code cho phép config model và endpoint qua file ~/.claude/settings.json. Đây là config mình đang dùng (với 9Router local - nếu bạn cũng dùng 9Router local thì copy thẳng, chỉ cần thay API key):
Giải thích:
ANTHROPIC_BASE_URL: endpoint local của router (chạy trên máy, port 20128)ANTHROPIC_AUTH_TOKEN: API key của routerANTHROPIC_DEFAULT_OPUS_MODEL: routekr/claude-opus-4.6- Opus chạy qua Kiro, đây là model chính (supervisor)ANTHROPIC_DEFAULT_SONNET_MODEL: routecx/gpt-5.5- GPT-5.5 chạy qua Codex, đây là model cho sub-agentANTHROPIC_DEFAULT_HAIKU_MODEL: cũng trỏ về GPT-5.5 cho các task nhẹ
Prefix kr/ và cx/ là cách 9Router phân biệt provider (mỗi router có cách đặt tên riêng). kr = Kiro, cx = Codex/OpenAI.
Điểm quan trọng: Claude Code chỉ có 3 slot model: opus, sonnet, và haiku. Không có tên tuỳ ý. Vậy nên cách mình tận dụng là:
- opus = model chính, chạy conversation, làm supervisor
- sonnet = model cho sub-agent (spawn agent sonnet)
- haiku = model cho task nhẹ nhất
Bạn map 3 slot này sang bất kỳ model nào qua router. Trong trường hợp của mình: opus → Kiro Opus 4.6, sonnet và haiku → GPT-5.5.
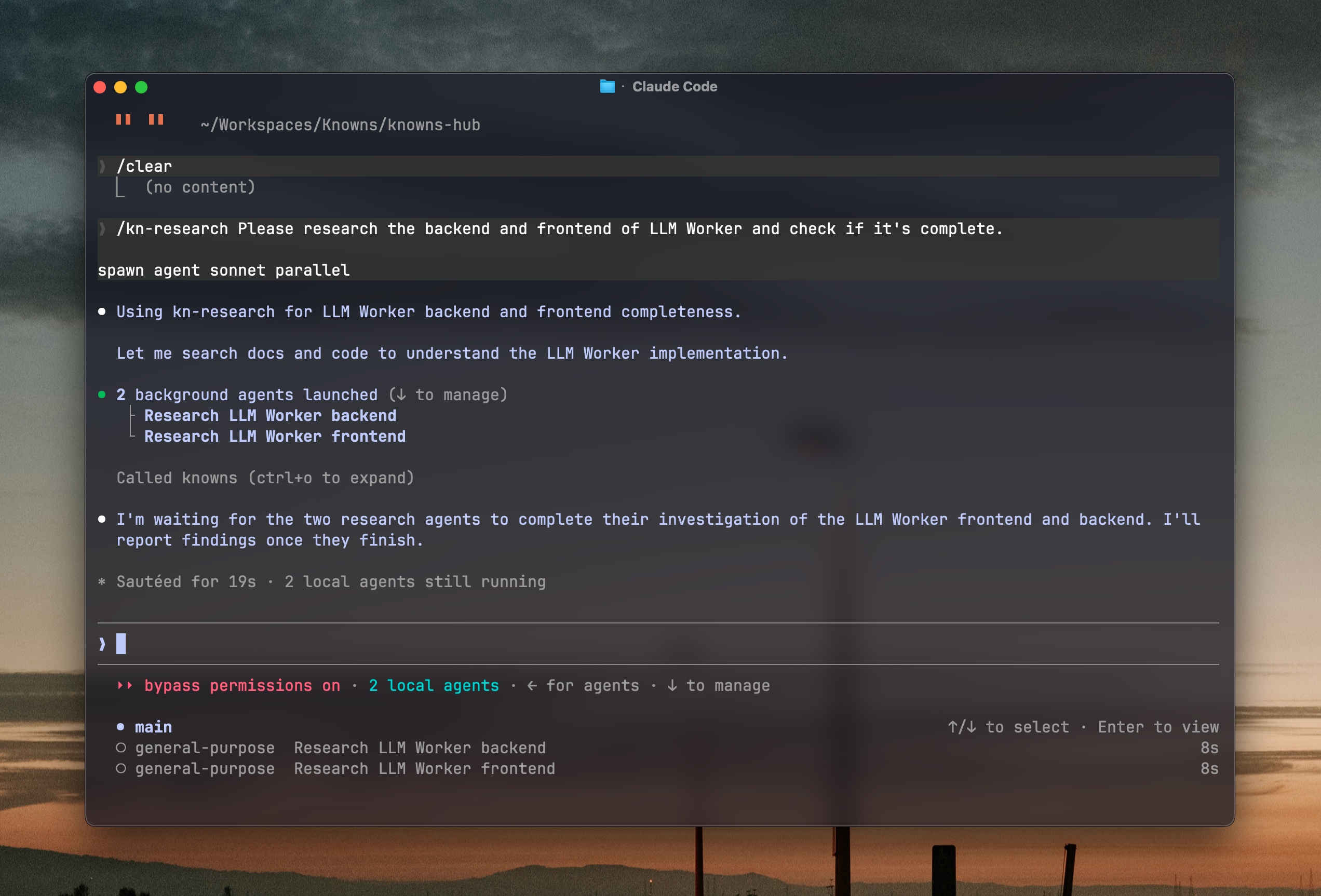
Với config này, khi mình dùng Claude Code bình thường, Opus sẽ là model chính. Khi spawn sub-agent bằng spawn agent sonnet, Claude Code sẽ tự dùng model sonnet đã config - tức GPT-5.5.
Đây là điểm hay: Claude Code có sẵn tính năng sub-agent (Agent tool). Bạn không cần cài thêm gì. Chỉ cần config đúng model routing, rồi khi gõ "spawn agent sonnet" hoặc để Opus tự spawn, nó sẽ dùng model sonnet đã map trong settings.
Bước 3: Spawn sub-agent - tính năng built-in của Claude Code
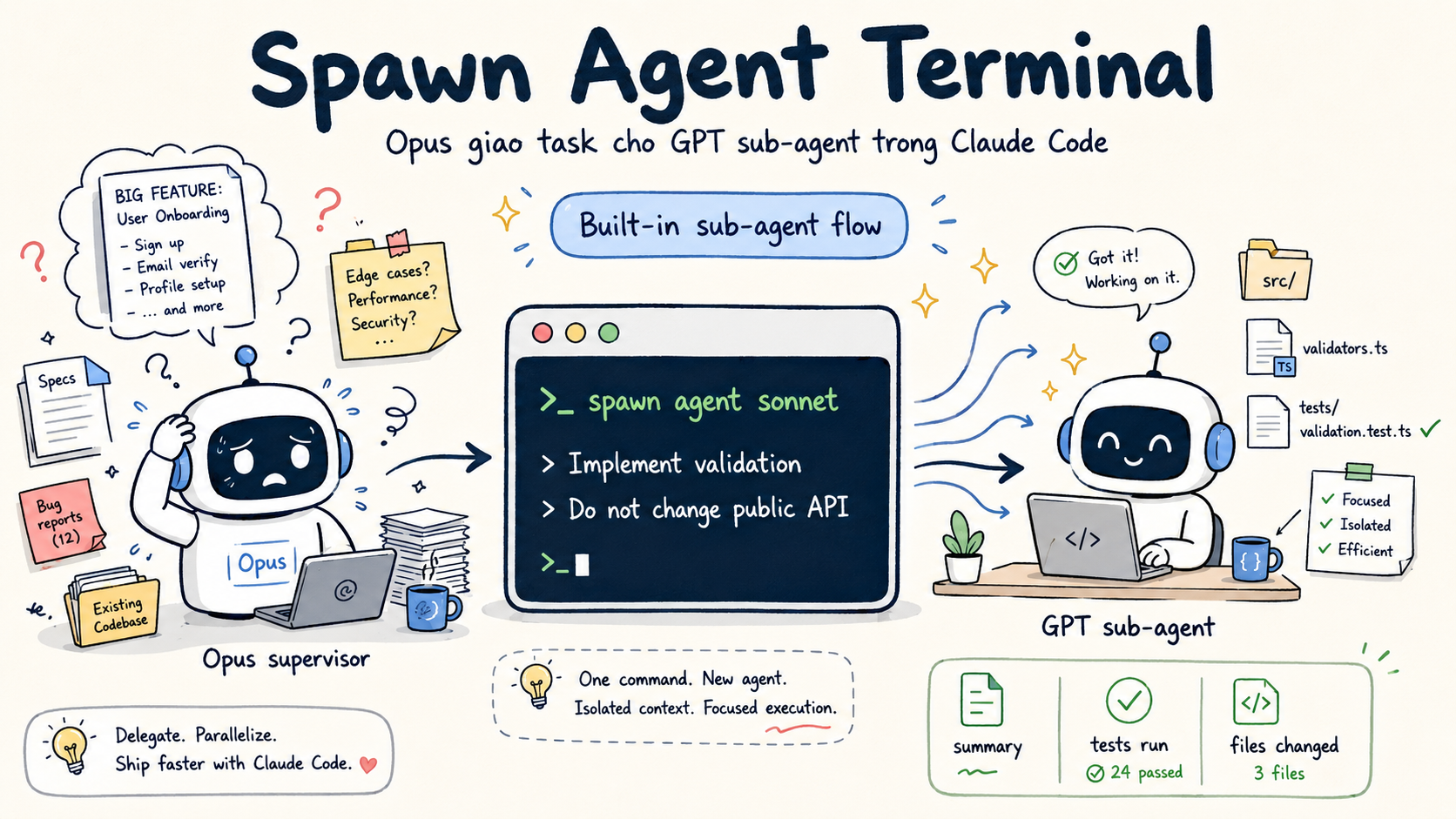
Đây là phần nhiều người không biết: sub-agent là tính năng có sẵn trong Claude Code. Bạn không cần cài plugin, không cần MCP server riêng, không cần script wrapper.
Claude Code có một tool gọi là Agent. Khi model chính (Opus) cần giao việc cho agent khác, nó có thể tự spawn một agent con chạy model khác. Hoặc bạn gõ trực tiếp:
Với config ở bước 2, sonnet sẽ map sang cx/gpt-5.5. Tức là GPT-5.5 sẽ xử lý task đó trong một context riêng biệt, không ảnh hưởng conversation chính của Opus.
Điểm hay:
- Sub-agent chạy trong môi trường riêng, không làm loãng context của supervisor
- Opus vẫn giữ nguyên conversation và có thể review output khi sub-agent xong
- Có thể spawn nhiều sub-agent song song cho các task độc lập
- Sub-agent có quyền đọc/sửa file, chạy command - giống một dev thật đang làm cùng
Cách dùng trong thực tế:
Hoặc ngắn hơn nếu context đã rõ:
Rồi Opus sẽ tự truyền instruction phù hợp dựa trên plan đã có.
Phân chia nhiệm vụ: khi nào Opus, khi nào GPT?
Đây là phần mình thấy quan trọng hơn cả setup.
Setup xong mà chia task tệ thì vẫn loạn. Model mạnh + model nhanh không tự động tạo workflow tốt. Cần biết việc nào nên giao cho ai.
Không chỉ implement - sub-agent cũng có thể research
Một điều mình muốn nói sớm: sub-agent không chỉ để code. Bạn hoàn toàn có thể spawn sub-agent để tìm hiểu, đọc code, research trước khi implement.
Ví dụ với một feature lớn, mình hay tách kiểu:
Hai agent này chạy song song, mỗi agent đọc một phần codebase. Opus nhận summary từ cả hai, rồi mới lên plan tổng.
Cách này giúp:
- Opus không phải đọc hết mọi file - tiết kiệm context window
- Mỗi sub-agent tập trung vào phần riêng - output rõ hơn
- Research song song - nhanh hơn đáng kể so với đọc tuần tự
Sau khi có research, mình lại tách implementation theo domain tương tự:
Tức là mỗi domain (backend, frontend, infra, test...) có thể là một sub-agent riêng, từ khâu tìm hiểu tới khâu implement. Opus chỉ cần supervise và ghép lại.
Dùng file trung gian để chuyển tiếp giữa các giai đoạn
Một vấn đề thực tế: sub-agent giai đoạn 1 (research) làm xong, sub-agent giai đoạn 2 (implement) làm sao biết kết quả?
Cách mình hay dùng là để sub-agent ghi output ra file. File đó trở thành "bản giao việc" cho agent tiếp theo.
Ví dụ:
File .agent/notes/billing-research.md sau khi agent xong có thể trông như:
Rồi phase 2:
Sub-agent giai đoạn 2 không cần đọc lại toàn bộ codebase. Nó chỉ cần đọc file tóm tắt từ giai đoạn 1 là đủ context để implement đúng.
Mình hay dùng folder .agent/notes/ hoặc .agent/handoff/ cho mấy file kiểu này. Gitignore nó nếu không muốn commit.
Nhưng không nhất thiết phải tự tạo file thủ công. Bạn có thể dùng:
- Backlog.md - tạo task có phần notes/output, agent sau đọc task đó để lấy context
- Knowns - dùng
appendNotesđể ghi kết quả vào task, hoặc tạo doc riêng cho mỗi giai đoạn - Markdown tự cấu trúc - folder
docs/handoff/hoặc bất kỳ convention nào team bạn quen
Ý tưởng đều giống nhau: có một chỗ ghi lại "giai đoạn trước làm xong gì, phát hiện gì, quyết định gì" để giai đoạn sau đọc được mà không cần hỏi lại.
File trung gian không cần đẹp. Nó chỉ cần đủ thông tin để agent tiếp theo không phải hỏi lại hoặc đọc lại từ đầu. Nghĩ như bản bàn giao ca cho đồng nghiệp.
Opus nên làm gì?
Mình thường để Opus xử lý các phần cần suy luận sâu và giữ bối cảnh tổng:
- phân tích yêu cầu mơ hồ
- đọc architecture
- tìm rủi ro
- chia task
- quyết định thứ tự implement
- review code
- check xem sub-agent có đi lệch không
- tổng hợp context từ nhiều nguồn
- viết spec/plan
- xử lý bug khó
- ra quyết định đánh đổi (trade-off)
GPT sub-agent nên làm gì?
GPT sub-agent hợp với các task có scope rõ:
- implement một function
- thêm test
- update type
- sửa lint
- refactor nhỏ
- migrate config đơn giản
- thêm component theo pattern có sẵn
- viết docs ngắn theo outline
- tìm usage của một API trong repo
- kiểm tra một nhóm file cụ thể
Sub-agent càng ít phải tự đoán, output càng ổn. Hãy giao việc bằng goal, scope, ràng buộc, và kết quả mong đợi.
Việc không nên giao cho sub-agent
Có vài thứ mình hạn chế giao thẳng cho sub-agent GPT nếu chưa có supervisor plan:
- đổi architecture lớn
- quyết định database schema mới
- thay public API
- refactor xuyên nhiều module
- xoá code cũ
- sửa security-sensitive flow
- merge output từ nhiều agent
- quyết định đánh đổi về product
Không phải GPT không làm được. Nhưng nếu đây là task ảnh hưởng nhiều nơi, mình muốn Opus giữ quyền điều phối và review.
Quản lý context: đừng cố chấp một tool
Một điểm mình muốn nhấn mạnh: để workflow supervisor/sub-agent chạy tốt, bạn cần có cách quản lý context. Nhưng không nhất thiết phải dùng đúng một tool nào.
Mình đang dùng Knowns vì mình thích có MCP-based project memory system: task, docs, memory, retrieve, validation nằm chung một lớp. Khi supervisor cần context, nó có thể search/retrieve thay vì mình paste lại từ đầu.
Nhưng bạn hoàn toàn có thể dùng cách khác:
- Backlog.md - một hệ thống quản lý task bằng markdown, nhẹ, dễ dùng với agent
TODO.mdhoặctasks.mdtự viết- folder
docs/ - file
decisions.md - Notion/Linear/Jira nếu team đã dùng
- hoặc một hệ thống markdown tự cấu trúc
Quan trọng không phải tên tool. Quan trọng là supervisor agent có chỗ để biết:
- task hiện tại là gì
- scope nằm ở đâu
- quyết định cũ là gì
- file nào liên quan
- tiêu chí hoàn thành là gì
- cái gì không được đụng
- đã thử gì và fail ra sao
Ví dụ một backlog.md đơn giản cũng đủ dùng:
Rồi bạn nói với supervisor:
- Backlog.md - Hệ thống quản lý task bằng markdown. Nhẹ, dễ dùng với agent, không cần setup phức tạp.
- Knowns - MCP-based project memory system. Quản lý task, docs, memory, và context cho agent trong một lớp.
Đừng cố chấp vào một tool duy nhất. Hệ thống tốt là hệ thống giúp supervisor agent giữ context đúng, không phải hệ thống có tên nghe xịn nhất.
Ví dụ workflow thực tế
Giả sử mình cần làm feature:
Thêm billing usage page cho workspace, hiển thị số request đã dùng, limit hiện tại, và warning khi gần chạm limit.
Nếu để một model làm hết, prompt thường sẽ rất to. Với supervisor/sub-agent, mình tách như sau.
1. Opus phân tích trước
Output mình kỳ vọng từ Opus:
2. Spawn sub-agent cho từng phần
Mỗi sub-agent chỉ đụng phần của mình. Opus không cần theo dõi chi tiết từng dòng code - chỉ cần đọc summary và review diff.
3. Opus tổng hợp và review
Đây là chỗ model mạnh có giá trị. Nó nhìn xuyên nhiều output, phát hiện chỗ không khớp, và giữ feature không bị mỗi agent kéo một hướng.
Debug lỗi thường gặp
- Sai model name / prefix: route cần đúng prefix provider, ví dụ
kr/claude-opus-4.6, không phảiclaude-opus-4.6. Tương tự GPT cầncx/gpt-5.5. - Router chưa chạy:
curl http://127.0.0.1:20128/v1/models -H "Authorization: Bearer $ANTHROPIC_AUTH_TOKEN"- nếu connection refused thì cần start router. - Sai biến env: Claude Code dùng
ANTHROPIC_AUTH_TOKEN, không phảiANTHROPIC_API_KEY. - Session cũ: sửa
settings.jsonxong cần restart Claude Code để load config mới. - Sai format: route GPT chỉ nhận OpenAI format mà router chưa chuyển đổi → lỗi body/schema. Kiểm tra chế độ tương thích.
Tips để workflow đỡ loạn
-
Đừng spawn agent trước khi có plan. Task còn mơ hồ thì để supervisor làm rõ trước.
-
Mỗi sub-agent một nhiệm vụ. Đừng giao "implement backend, frontend, tests, and refactor". Tách ra.
-
Ghi ràng buộc rõ. Mấy câu như "Do not change public API", "Do not add dependencies" rất đáng tiền.
-
Supervisor phải review diff. Sub-agent làm xong không có nghĩa là xong.
Khi nào workflow này không đáng dùng?
Không phải task nào cũng cần supervisor/sub-agent.
Sửa typo, update copy, rename biến, fix lỗi nhỏ → dùng một agent là đủ.
Mình dùng mô hình này khi task có:
- nhiều bước
- nhiều module
- cần đọc nhiều file
- cần plan trước
- cần review kỹ
- có rủi ro trôi context
- muốn tiết kiệm credit model mạnh
- có nhiều phần implementation lặp lại
Workflow tốt không phải workflow phức tạp nhất. Workflow tốt là workflow vừa đủ để giảm lỗi và giảm chi phí cho loại task đang làm.
Kết
Thay vì một model làm tất cả, mình dùng:
- Opus = nghĩ sâu, giữ context, supervise, review
- GPT = chạy nhanh, làm task nhỏ, implement theo scope
- Router (9Router, OmniRouter, CLI API Proxy...) = route model và gom provider
- Knowns/backlog/docs = giữ context và task state
- Claude Code = runtime làm việc hằng ngày
Cách này giúp mình tiết kiệm credit hơn, task lớn ít trôi hơn, tốc độ tốt hơn, và output ổn định hơn khi làm project thật.
Nhưng phần quan trọng không chỉ là tool. Phần quan trọng là cách chia việc.
Nếu anh em đang dùng Claude Code + Kiro + GPT, có thể thử bắt đầu nhỏ:
- Setup router với 2 route: Opus supervisor và GPT coder.
- Dùng Opus để plan một task vừa vừa.
- Spawn một GPT sub-agent cho một phần implementation nhỏ.
- Bắt Opus review diff.
- Ghi task/context vào Knowns,
backlog.md, hoặc một file markdown có cấu trúc.
Làm vài vòng sẽ thấy workflow nào hợp với mình.
Đừng biến tool thành tôn giáo. Mục tiêu cuối cùng vẫn là: context rõ hơn, code ít sai hơn, chi phí hợp lý hơn, và mình đỡ phải giải thích lại từ đầu mỗi lần mở terminal.


