
Agent Memory: đừng feed mọi thứ, cũng đừng quá tiết kiệm
Memory của agent không phải là dump hết mọi thứ vào prompt. Nó là bài toán feed đúng context, đúng lúc, đúng lượng.
May 19, 2026 · 14 min read
Mấy tháng gần đây mình dùng agent coding khá nhiều. Claude Code, Cursor, Copilot, rồi cả mấy workflow tự build quanh đó. Càng dùng nhiều mình càng thấy một chuyện lặp đi lặp lại.
Context quyết định rất lớn tới chất lượng output.
Nghe thì hiển nhiên. Nhưng khi bắt tay vào dùng thật, nó lại thành một bài toán khá khó chịu: đừng feed mọi thứ cho agent, nhưng cũng đừng quá tiết kiệm context.
Hai câu này nghe như đá nhau. Nhưng thực ra đó chính là bài toán thực tế.
Context là nhiên liệu, nhưng không phải cứ đổ đầy là chạy ngon
Khi làm với agent, mình hay có cảm giác rất muốn "cho nó biết hết". Cho nó đọc cả repo. Cho nó đọc toàn bộ docs. Cho nó history từ đầu tới cuối. Cho nó tất cả quyết định kỹ thuật đã từng có.
Ý tưởng nghe hợp lý mà. Agent càng biết nhiều thì càng làm đúng hơn, đúng không?
Không hẳn.
Mình từng có vài lần paste quá nhiều thứ vào prompt. Một đống file, một đống rule, một đống giải thích. Kết quả là agent trả lời rất tự tin, nhưng lại miss đúng phần quan trọng nhất.
Nó nhớ vài chi tiết phụ. Nó quote lại mấy câu mình không cần. Nhưng tới chỗ cần bám sát convention chính thì lại làm lệch.
Lúc đó mình mới nhận ra: memory không phải là "nhồi càng nhiều càng tốt". Memory tốt là giúp agent giữ focus.
Context không chỉ là thông tin. Context còn là sự ưu tiên.
Nếu mọi thứ đều quan trọng, thì không có thứ gì thật sự quan trọng nữa.
Vì sao feed mọi thứ không work
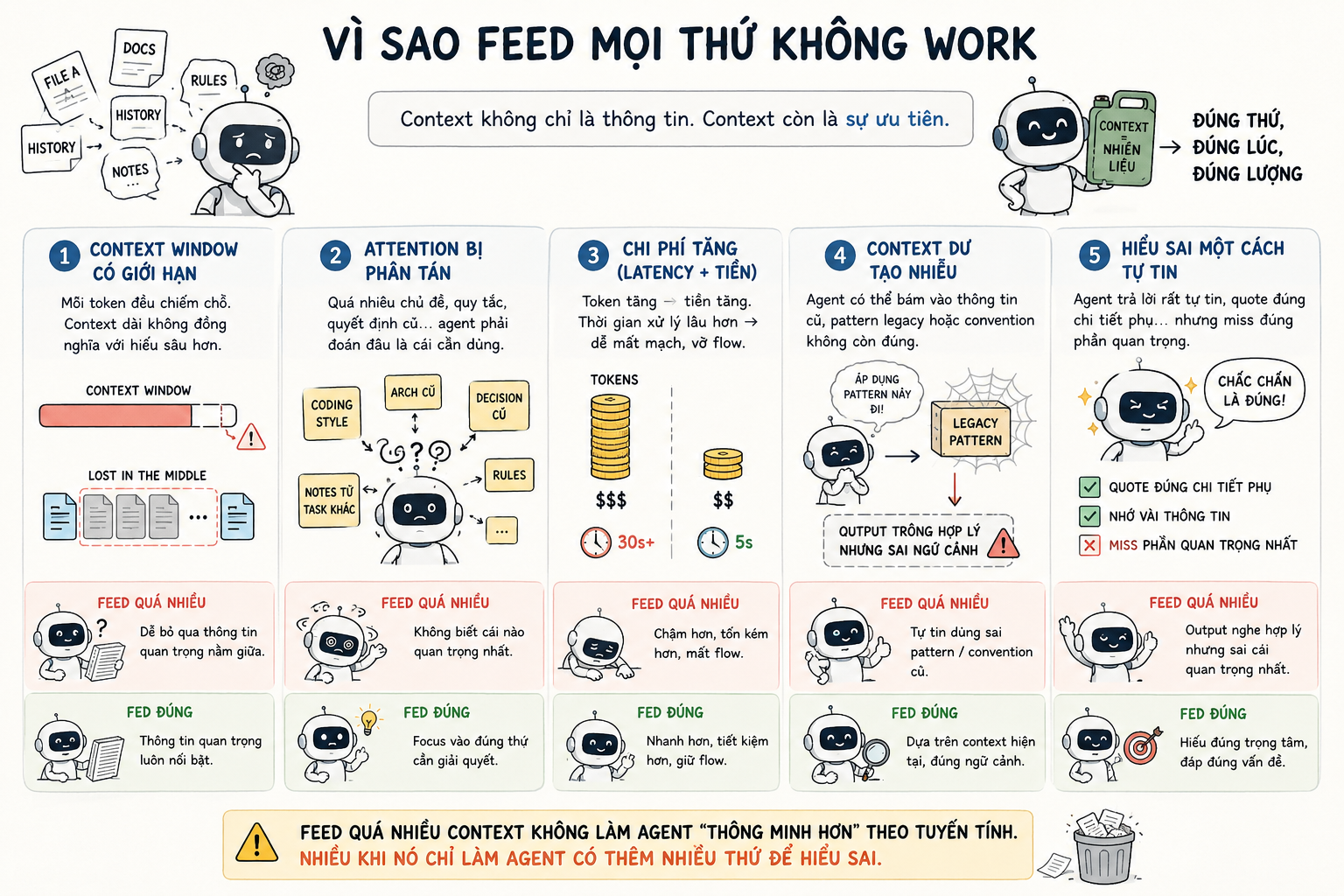
Lý do đầu tiên khá dễ thấy: context window có giới hạn.
Dù model ngày càng hỗ trợ context dài hơn, nó vẫn không phải cái kho vô hạn. Mỗi token đưa vào đều chiếm chỗ. Mỗi đoạn text thừa đều làm agent phải "nhìn" qua nhiều thứ hơn trước khi trả lời.
Và context dài không đồng nghĩa với hiểu sâu hơn.
Có một vấn đề khá nổi tiếng là lost in the middle. Khi context quá dài, model thường dễ chú ý phần đầu và phần cuối hơn, còn thông tin nằm giữa có thể bị bỏ qua. Mình thấy chuyện này rất giống khi đọc một file docs dài 50 trang. Không phải cứ mở hết ra là mình hiểu hết.
Lý do thứ hai là attention bị phân tán.
Nếu prompt vừa có coding style, vừa có architecture cũ, vừa có decision đã obsolete, vừa có notes từ task khác, agent sẽ phải tự đoán phần nào relevant. Mà agent đoán thì hên xui. Đoán đúng thì ngon. Đoán sai thì mình ngồi sửa.
Lý do thứ ba là chi phí.
Token tăng thì tiền tăng. Latency tăng. Mỗi lần agent suy nghĩ lâu hơn, mình cũng mất mạch hơn. Đặc biệt khi đang code, cái flow rất dễ vỡ. Chờ 30 giây khác hẳn chờ 5 giây.
Và lý do cuối cùng: context dư dễ tạo nhiễu.
Agent có thể bám vào một đoạn cũ mà mình quên xoá. Hoặc lấy một convention từ module khác áp vào module hiện tại. Hoặc thấy một pattern legacy rồi tưởng đó là style mới.
Cái này khá nguy hiểm. Vì output nhìn có vẻ hợp lý. Nhưng nó hợp lý theo context sai.
Feed quá nhiều context không làm agent "thông minh hơn" theo tuyến tính. Nhiều khi nó chỉ làm agent có thêm nhiều thứ để hiểu sai.
Nhưng tiết kiệm quá cũng vỡ
Ở chiều ngược lại, mình cũng từng mắc lỗi vì quá tiết kiệm context.
Prompt kiểu: "thêm tính năng X vào repo này". Agent tự search một chút, đọc vài file, rồi implement. Nhìn qua có vẻ ổn. Nhưng khi review kỹ thì style lệch, naming không khớp, test thiếu, hoặc nó tạo abstraction mới trong khi project đã có sẵn pattern.
Vấn đề không phải agent lười. Vấn đề là mình không cho nó đủ tín hiệu.
Một agent thiếu context sẽ phải assume.
Nó sẽ assume project dùng convention phổ biến. Assume folder nên đặt theo cách nó từng thấy. Assume hàm này nên trả về kiểu kia. Assume decision cũ chưa tồn tại. Assume mình muốn "best practice" chung chung, trong khi codebase hiện tại có lý do riêng.
Và khi agent assume sai, nó thường không nói "mình đang đoán nha". Nó chỉ viết code.
Đây là chỗ mình thấy hơi đau. Vì output của LLM thường rất trôi. Nó làm mình có cảm giác mọi thứ đều ổn. Nhưng cái sai nằm ở ranh giới nhỏ: một naming convention, một edge case, một business rule, một decision đã được make từ tháng trước.
Là một người hay quên như mình, chuyện này xảy ra khá thường. Nhiều khi chính mình còn không nhớ decision cũ nằm ở đâu, huống chi agent.
Vậy nên tiết kiệm context quá cũng không phải hay. Nó chỉ đẩy phần thiếu hụt sang hallucination.
Sweet spot nằm ở "đúng thứ, đúng lúc, đúng lượng"
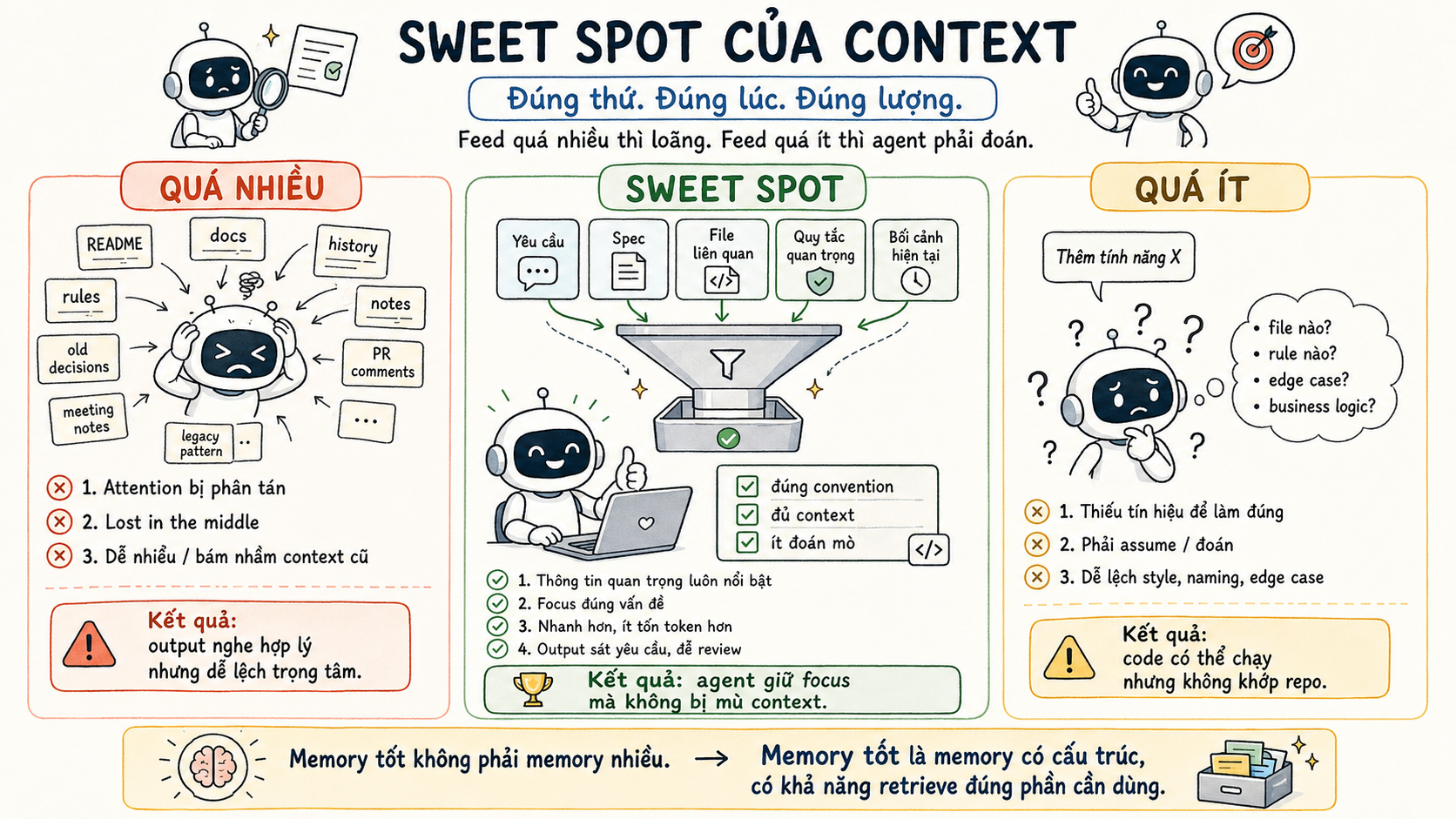
Mình nghĩ cái paradox này thực ra không conflict.
"Đừng feed mọi thứ" và "đừng quá tiết kiệm" là hai mặt của cùng một nguyên tắc: feed đúng thứ, đúng lúc, đúng lượng.
Memory không phải là dump toàn bộ repo vào prompt. Memory là khả năng biết lúc nào cần gì, và lấy đúng phần đó ra.
Giống con người thôi.
Khi mình sửa một bug trong auth flow, mình không load toàn bộ kiến thức lập trình từ hồi học PHP vào đầu. Mình giữ vài thứ key: bug đang là gì, file nào liên quan, flow hiện tại chạy ra sao, convention của repo là gì.
Nếu cần thêm, mình search. Mở docs. Hỏi đồng nghiệp. Xem git history. Đọc test.
Mình không nhớ mọi thứ cùng lúc. Nhưng mình nhớ đủ để biết phải tìm ở đâu.
Agent cũng nên vậy.
Memory tốt không phải là memory nhiều. Memory tốt là memory có cấu trúc, có đường dẫn, có khả năng retrieve.
Các layer memory mình hay nghĩ tới
Khi làm việc với agent, mình hay tách memory thành vài layer. Không phải framework gì ghê gớm. Chỉ là cách mình tự tránh việc nhồi hết vào một prompt.
Layer đầu tiên là system prompt hoặc mấy file như CLAUDE.md, AGENTS.md.
Đây là phần luôn có mặt. Vì luôn có mặt nên nó nên ngắn. Nó nên chứa rules, conventions, và cách agent phải làm việc trong repo. Không nên biến nó thành cái thùng chứa toàn bộ architecture.
Ví dụ rule kiểu "đừng commit nếu chưa được yêu cầu", "dùng pnpm", "test command là gì", "style viết blog ra sao". Những thứ này đáng ở layer luôn-on.
Layer thứ hai là project docs và specs.
Đây là phần agent load khi cần. Architecture, ADR, domain notes, API contract, spec của feature. Mấy thứ này quan trọng, nhưng không phải task nào cũng cần.
Nếu đang sửa typo trong blog post, agent không cần đọc toàn bộ architecture. Nếu đang đổi payment flow, agent chắc chắn cần đọc decision cũ.
Layer thứ ba là task context.
Đây là context của việc đang làm ngay lúc này: yêu cầu, acceptance criteria, file liên quan, constraint, test cần chạy. Layer này nên rất focused. Task càng nhỏ thì context càng gọn.
Mình thấy đây là lý do chia nhỏ task vẫn rất hiệu quả khi dùng agent. Không phải vì agent không làm được task lớn. Mà vì task nhỏ giúp context ít bị loãng.
Layer thứ tư là conversation history.
Phần này thường tự động. Mình nói gì trước đó, agent đã thử gì, lỗi nào vừa xảy ra. Nhưng conversation dài quá thì sẽ bị compact hoặc mất chi tiết. Đừng coi nó là nguồn sự thật duy nhất.
Layer cuối là persistent memory.
Đây là những thứ sống qua nhiều session: convention ổn định, decision quan trọng, preference cá nhân, pattern hay lặp lại. Nó không cần xuất hiện nguyên văn trong mọi prompt. Nhưng agent cần có cách tìm lại.
Mình hay nghĩ memory giống cái bàn làm việc. Trên bàn chỉ nên có thứ đang dùng. Còn sách, hồ sơ, note cũ vẫn cần, nhưng nên nằm trên kệ có nhãn.
CLAUDE.md dài quá cũng là một mùi
Mình từng có phase muốn nhét rất nhiều thứ vào CLAUDE.md. Tánh khó bỏ thật. Cứ sợ agent không biết, nên thêm vào. Sợ quên rule, nên thêm vào. Sợ lần sau nó làm sai, lại thêm vào.
Sau một thời gian, file đó biến thành một mini-wiki.
Nghe thì tiện. Nhưng dùng thật mới thấy không ổn. Vì mọi task đều phải mang theo cái wiki đó. Sửa một cái component nhỏ cũng load cả đống thông tin không liên quan.
Giờ mình thích cách khác hơn: CLAUDE.md hoặc AGENTS.md chỉ chứa rule nền và chỉ đường.
Kiểu:
Còn chi tiết thì để trong docs riêng. Khi cần, agent tự pull.
Nói vui là CLAUDE.md nên giống lễ tân, không phải thư viện quốc gia. Nó chỉ cho agent biết phải đi đâu, không cần tự ôm hết mọi cuốn sách.
Để agent tự search/read thay vì paste cả file
Một tip mình rất recommend: đừng paste cả file vào prompt nếu agent có thể tự đọc.
Thay vì copy 500 dòng code rồi nói "sửa giúp mình", mình thích nói rõ mục tiêu và chỉ đường:
Hoặc nếu có docs:
Cách này có hai lợi ích.
Một là prompt gọn hơn. Hai là agent tự tạo được map của vấn đề bằng hành động search/read. Nó không bị ép xử lý một cục text lớn do mình paste vào.
Tất nhiên, mình vẫn cần kiểm soát. Agent search sai chỗ thì phải kéo lại. Nhưng nhìn chung, cho agent quyền tìm context thường tốt hơn là tự nhồi context thủ công.
Review xem agent đang "nhớ" gì
Memory cũng có thể bị bẩn.
Nếu agent cứ lặp lại một rule sai, hoặc cứ assume một pattern không còn dùng nữa, có thể memory đang bị polluted. Không phải lúc nào lỗi cũng nằm ở model. Nhiều khi lỗi nằm ở context mình đưa vào.
Ví dụ mình từng thấy agent cứ cố thêm abstraction vì trong docs cũ có một đoạn nói về "service layer". Nhưng code hiện tại đã chuyển sang approach khác. Docs không được update, agent cứ bám vào đó.
Lúc này fix prompt không đủ. Phải fix memory.
Xoá note cũ. Update docs. Ghi rõ decision mới. Tách legacy pattern ra khỏi convention hiện tại.
Memory tốt cần được dọn. Giống note app vậy. Lúc mới dùng thì vui. Một năm sau không dọn thì thành bãi rác. Sinh viên nghèo như mình thì tiếc gì cũng giữ, nhưng context bẩn là agent trả giá liền.
Nếu agent sai cùng một kiểu nhiều lần, đừng chỉ sửa output. Hãy tìm xem nó đang lấy niềm tin sai đó từ đâu.
Knowns và cái đau "giải thích lại từ đầu"
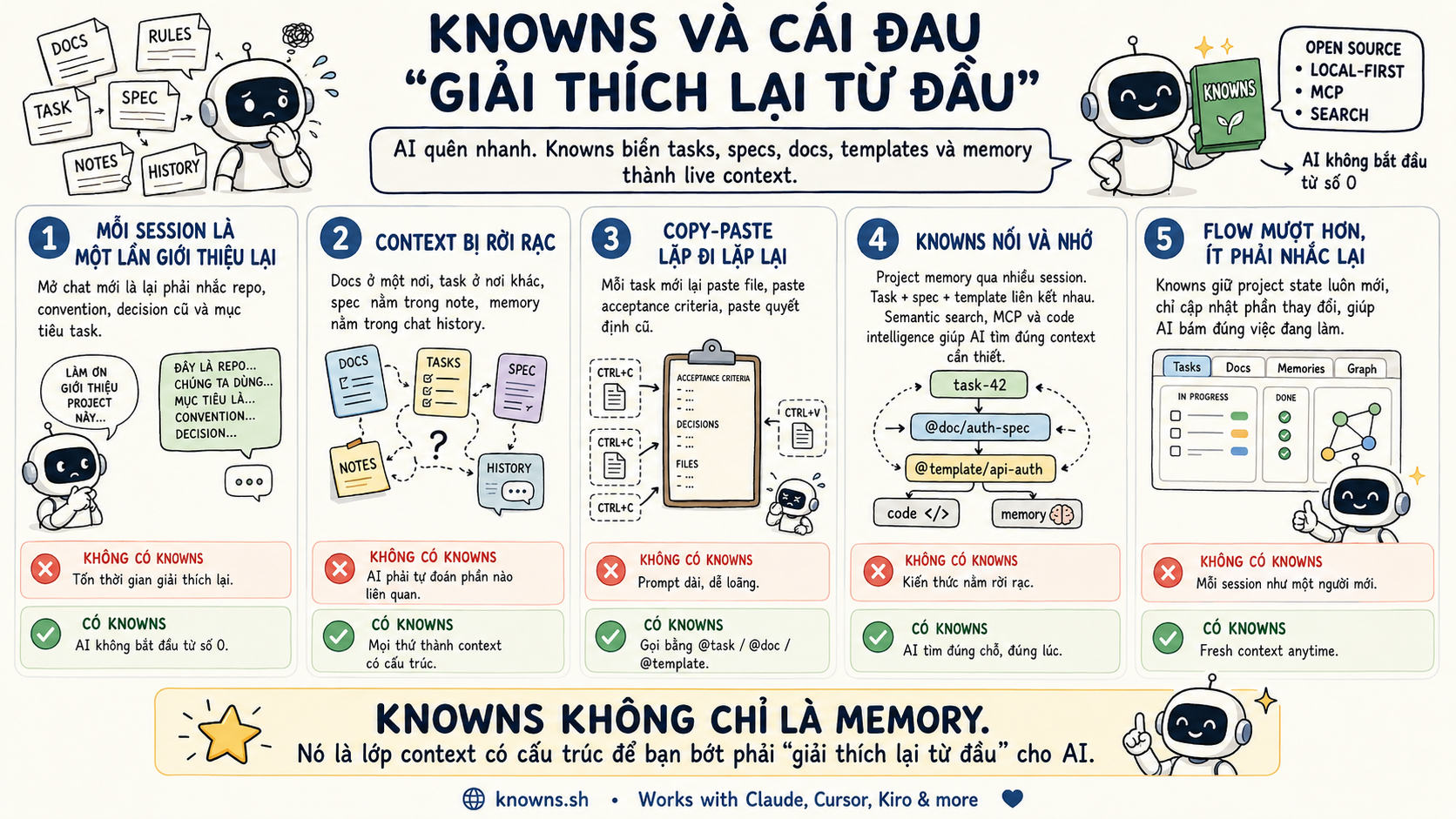
Một lý do mình đang build Knowns cũng đến từ chỗ này.
Mỗi khi muốn AI hiểu task đang làm, mình phải tự gõ lại context, giải thích lại mọi thứ. Làm hoài cũng mệt. Nhất là khi nhảy qua lại giữa nhiều project, nhiều feature, nhiều decision cũ.
Knowns là một CLI tool, một dự án open source mình đang build như layer Memory cho project. Ý tưởng khá đơn giản: thay vì tự nhập tay, bạn gõ @doc/architecture hay @task-123, AI tự đọc, tự hiểu phần liên quan.
Không cần copy-paste context mỗi lần. Không cần nhồi mọi thứ vào một file instruction khổng lồ. Task, docs, memory nằm có cấu trúc hơn, và agent có đường để retrieve khi cần.
Mình không nghĩ đây là câu trả lời duy nhất. Nhưng với workflow của mình, nó giải quyết đúng cái đau: context bị rời rạc, memory bị phân mảnh, và mỗi session AI lại như một người mới vào team.
Nếu anh em thấy hướng này thú vị, một star ⭐ cũng là động lực lớn cho mình tiếp tục phát triển project.
Vài nguyên tắc mình đang dùng
Tới giờ mình vẫn đang mò. Nhưng có vài nguyên tắc mình thấy khá ổn.
Một là giữ file instruction ngắn. CLAUDE.md, AGENTS.md, hoặc system prompt nên chứa rule nền, không chứa toàn bộ kiến thức dự án.
Hai là chia task nhỏ. Task nhỏ làm context focused hơn, review dễ hơn, và agent ít có cơ hội đi lạc hơn.
Ba là dùng reference thay vì paste. @doc/..., @task-..., file path cụ thể, hoặc câu lệnh "search trước rồi đọc phần liên quan". Cho agent đường đi thay vì bê cả nhà kho ra trước mặt nó.
Bốn là lưu decision quan trọng ở chỗ bền hơn conversation. Chat history không phải database. Nếu một quyết định sẽ còn ảnh hưởng về sau, hãy đưa nó vào docs, task note, hoặc persistent memory.
Năm là dọn memory. Context cũ, docs sai, convention obsolete — mấy thứ này nguy hiểm hơn là không có context. Vì nó làm agent sai một cách tự tin.
Và sáu là review output như bình thường. Memory tốt giúp agent làm đúng hơn, nhưng không thay thế trách nhiệm đọc lại. Nhất là với code.
Kết
Cái paradox "đừng feed mọi thứ, cũng đừng quá tiết kiệm" không thật sự conflict.
Nó chỉ nói cùng một chuyện từ hai phía: context phải có chọn lọc.
Feed quá nhiều thì agent loãng. Feed quá ít thì agent đoán. Cả hai đều dẫn tới output tệ, chỉ tệ theo hai kiểu khác nhau.
Mình nghĩ hướng đúng là xây memory có cấu trúc. Cái gì luôn cần thì để ở instruction. Cái gì theo project thì để docs. Cái gì theo task thì gắn với task. Cái gì lâu dài thì lưu vào persistent memory. Và quan trọng nhất: agent phải biết cách tìm lại đúng thứ khi cần.
Memory tốt không phải memory nhiều. Memory tốt là memory giúp agent giữ focus mà vẫn không bị mù context.
See yah.
Các hình minh hoạ trong bài được tạo bằng ChatGPT để giúp người đọc dễ hình dung hơn.


